2.2-2.8
目录:
- VLMs / LLMs
- Qwen3-VL-Embedding + Reranker
- Andew Karpathy https://github.com/karpathy/nanochat update
- ObjEmbed
- A Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training
- BaseCV
- CoWTracker: Tracking by Warping instead of Correlation
- Mining Generalizable Activation Functions
- Other things (won’t provide any comments but just an announcement)
- OCR 的新 SOTA:GLM-OCR
- 边端侧多模态的新 SOTA:MiniCPM-o 4.5
- Personal AI assistant: openclaw.ai 在10天内涨了14W的star
- KIMI K-2.5: multimodal agentic model https://github.com/MoonshotAI/Kimi-K2.5
- Step-3.5 Flash: Stepfun’s most capable open-source foundation model https://github.com/stepfun-ai/Step-3.5-Flash
VLMs:
a. Qwen3-VL-Embedding + Reranker: https://github.com/QwenLM/Qwen3-VL-Embedding/blob/main/assets/qwen3vlembedding_technical_report.pdf
机构: 阿里
这些模型基于我们最近开源的Qwen3-VL模型构建,专为多模态信息检索和跨模态理解场景设计。
核心特性
- 多模态通用性 两个模型系列均可在统一框架内处理包含文本、图像、截图和视频的输入。它们在图文检索、视频文本匹配、视觉问答(VQA)以及多模态内容聚类等多样化任务中达到了业界领先水平。
- 统一表示学习(Embedding) 通过充分利用Qwen3-VL基础模型的优势,Qwen3-VL-Embedding模型能够生成语义丰富的向量表示,在共享空间中同时捕获视觉和文本信息,从而实现高效的跨模态相似度计算和检索。
- 高精度重排序(Reranker) 我们同步提供Qwen3-VL-Reranker系列作为 Embedding模型的补充。Qwen3-VL-Reranker接收输入对(Query, Document), 其中查询和文档均可包含任意单一或混合模态——并输出精确的相关性分数。在实际检索场景中,Embedding和Reranker模型通常协同工作:Embedding模型负责初始召回阶段,Reranker模型负责重排序阶段,这种两阶段流程显著提升了最终检索精度。
- 卓越的实用性 继承Qwen3-VL的多语言能力,该系列支持超过30种语言,适合全球化应用。模型提供灵活的向量维度选择、可定制的任务指令,以及向量量化后的强劲性能。这些特性使开发者能够轻松将两个模型集成到现有流程中,用于需要强大跨语言和跨模态理解能力的应用场景。
使用指南
Embedding 和 Reranking 模型通常在检索系统中协同使用,形成高效的两阶段检索流程:
1). 召回阶段:Embedding 模型执行初始召回,从海量数据中快速检索出大量候选结果。embedding 可以存下来,然后进行快速的相似度比对,类似于clip。这一步是将recall拉高。
from scripts.qwen3_vl_embedding import Qwen3VLEmbedder
import numpy as np
import torch
# Define a list of query texts
queries = [
{"text": "A woman playing with her dog on a beach at sunset."},
{"text": "Pet owner training dog outdoors near water."},
{"text": "Woman surfing on waves during a sunny day."},
{"text": "City skyline view from a high-rise building at night."}
]
# Define a list of document texts and images
documents = [
{"text": "A woman shares a joyful moment with her golden retriever on a sun-drenched beach at sunset, as the dog offers its paw in a heartwarming display of companionship and trust."},
{"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"},
{"text": "A woman shares a joyful moment with her golden retriever on a sun-drenched beach at sunset, as the dog offers its paw in a heartwarming display of companionship and trust.", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"}
]
# Specify the model path
model_name_or_path = "Qwen/qwen3-vl-embedding-2B"
# Initialize the Qwen3VLEmbedder model
model = Qwen3VLEmbedder(model_name_or_path=model_name_or_path)
# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# model = Qwen3VLEmbedder(model_name_or_path=model_name_or_path, dtype=torch.float16, attn_implementation="flash_attention_2")
# Combine queries and documents into a single input list
inputs = queries + documents
embeddings = model.process(inputs)
# Compute similarity scores between query embeddings and document embeddings
similarity_scores = (embeddings[:4] @ embeddings[4:].T)
# Print out the similarity scores in a list format
print(similarity_scores.tolist())
# [[0.83203125, 0.74609375, 0.73046875], [0.5390625, 0.373046875, 0.48046875], [0.404296875, 0.326171875, 0.357421875], [0.1298828125, 0.06884765625, 0.10595703125]]2). 重排序阶段:Reranking 模型对候选结果进行精细化排序,基于重新计算的相关性分数为用户查询呈现最精确的结果。这一步是将上一步筛出来的结果进行细致比对,将precision拉高。
from scripts.qwen3_vl_reranker import Qwen3VLReranker
import numpy as np
import torch
# Specify the model path
model_name_or_path = "Qwen/Qwen3-VL-Reranker-2B"
# Initialize the Qwen3VLEmbedder model
model = Qwen3VLReranker(model_name_or_path=model_name_or_path)
# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# model = Qwen3VLReranker(model_name_or_path=model_name_or_path, dtype=torch.float16, attn_implementation="flash_attention_2")
# Combine queries and documents into a single input list
inputs = {
"instruction": "Retrieval relevant image or text with user's query",
"query": {"text": "A woman playing with her dog on a beach at sunset."},
"documents": [
{"text": "A woman shares a joyful moment with her golden retriever on a sun-drenched beach at sunset, as the dog offers its paw in a heartwarming display of companionship and trust."},
{"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"},
{"text": "A woman shares a joyful moment with her golden retriever on a sun-drenched beach at sunset, as the dog offers its paw in a heartwarming display of companionship and trust.", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"}
],
"fps": 1.0
}
scores = model.process(inputs)
print(scores)
# [0.8408790826797485, 0.6197134852409363, 0.7778129577636719]
b. Andew Karpathy https://github.com/karpathy/nanochat
单节点 8xH100,耗时 3.04 小时,成本约 73 美元,即可复现 1.5B 参数的 GPT-2 。成本降低约 600 倍。
- 架构细节:做减法与关键增量
- 激活与归一化的极简主义:
- ReLU² 激活:放弃了常用的 GELU,转而使用 F.relu(x).square()。这种激活函数更加稀疏,计算成本更低。
- 无参数 RMSNorm:移除了所有可学习的 gamma/beta 参数,仅保留归一化操作。既减少了参数量,性能也无负面影响。
- QK Normalization:在 RoPE 之后对 Q 和 K 进行归一化(q, k = norm(q), norm(k))。这一步彻底稳住了注意力机制的数值,不再需要 Attention Softcapping。
- Logit Softcapping:为防止数值溢出,Logits 被限制在 [-15, 15] 区间内(15 * tanh(logits / 15)),且始终以 float32 计算。
- 激活与归一化的极简主义:
- Attention 效率优化
- Flash Attention 3:采用 Native layout (B, T, H, D)。相比 PyTorch 的 SDPA,在 H100 上带来了约 9% 的吞吐提升。
- Sliding Window Attention (SSSL):采用“3层短窗口 (1024 tokens) + 1层全窗口 (2048 tokens)”的平铺模式。实验证明,这种混合模式在大幅节省计算量的同时,几乎不损失长上下文能力。
- Value Embeddings:模型在交替层(Alternating layers)引入了 Gated Value Embeddings。这一设计为 d24 模型增加了约 150M 的参数量(约占总参数量的 10%),但几乎没有增加 FLOPs。此外,模型采用了输入输出层参数不共享(Untied Embeddings)以及每层引入可学习标量,初始化为 1.0 和 0.1,这些微小改动的叠加带来了一致的性能提升。
# 伪代码逻辑展示 Value Embeddings 实现 ve = value_embeds[layer_idx](token_ids) # (B, T, kv_dim) gate = 2 * sigmoid(ve_gate(x[:, :, :32])) # range (0, 2) v = v + gate * ve
- Muon 优化器
- 分层策略
Karpathy 设定了一组极端的超参数值得注意:
AdamW:仅用于 Embeddings 和标量参数。
- lm_head:Learning Rate = 0.004
- wte + value_embeds:Learning Rate 高达 0.3
- x0_lambdas:设置了 beta1=0.96(通常默认 0.9),增加了动量惯性
Muon:专门用于处理所有的 2D 矩阵权重(Attention Projections, MLP weights)。
- Muon 的核心在于通过正交化更新来优化矩阵参数,主要包含以下特性:
- Polar Express 正交化:使用迭代 5 次的 Polar Express 算法替代传统的 Newton-Schulz 算法,强制更新量保持正交。
- 动量预热:采用了 Nesterov momentum,并在前 300 步内将动量参数从 0.85 线性增加至 0.95。
- Factored Variance Reduction:采用了类似 Adafactor 的方差缩减技术。
- Cautious Weight Decay:这是一个“Clear Win”。仅在梯度与参数方向一致(grad * param >= 0)时才应用权重衰减。
Karpathy 试图切回纯 AdamW,结果并不理想——大规模训练离不开 Muon。
- 分层策略
c. ObjEmbed https://github.com/WeChatCV/ObjEmbed/blob/main/README_zh.md https://arxiv.org/pdf/2602.01753
机构:中山大学,微信
要点:
- 研究团队发现,如果强行让一个 Token 同时学习分类和定位,会引发“优化冲突”。为此,他们巧妙地将物体拆解为两个互补的 Token:物体 Token (Object Token) 用于捕捉语义细节,IoU Token 则专门负责预测边界框的定位质量。
- ObjEmbed 具有极高效率。它并不需要像老牌模型那样对每个区域重复扫描,而是通过一种“全家桶”式的模板,将整张图像的全局信息和所有感兴趣区域(RoIs)组织成一个序列,仅需一次前向传播 (Single Forward Pass),就能同时导出全局图像嵌入、多个物体嵌入及其定位质量评分。即使一张图里有 100 个物体,总序列长度也通常在 2000 个 Token 以内,这意味着它可以在极小的显存占用下,利用 FlashAttention-2 等技术实现飞速计算
- 局部图像检索 (Local Image Retrieval) 任务中——即根据一段描述(如“一个穿着 8 号球衣的球员”)在成千上万张图中找到正确的那张——ObjEmbed 的表现比传统的全局嵌入模型足足高出了 20 个百分点,而且还支持I2I(即使没有针对性地进行训练)
结果:检测上效果比WeDetect有提升,但是ref上和WeDetect-Ref对应的参数量模型来比,优势并不明显。在global image retrieval上,4B略胜 Qwen3Embedding2B一筹,2B不如Qwen3Embedding2B。但是Qwen3Embedding没有4B,只有2B 8B。在 local image retrieval人物上,效果要比Qwen3-VL-Embedding-8B还要高20个点。
# 实例:
python infer_objembed.py --objembed_checkpoint /PATH/TO/OBJEMBED \
--wedetect_uni_checkpoint /PATH/TO/WEDETECT_UNI \
--image assets/demo.jpg \
--query "The car's license plate in HAWAII" \
--task rec \
--visualize
总结:虽然它目前仍受限于前端提议网络 (Proposal Generator) 的质量,但这种“物体导向”的表征逻辑无疑为多模态 AI 指明了方向
d. A Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training
机构:阿里
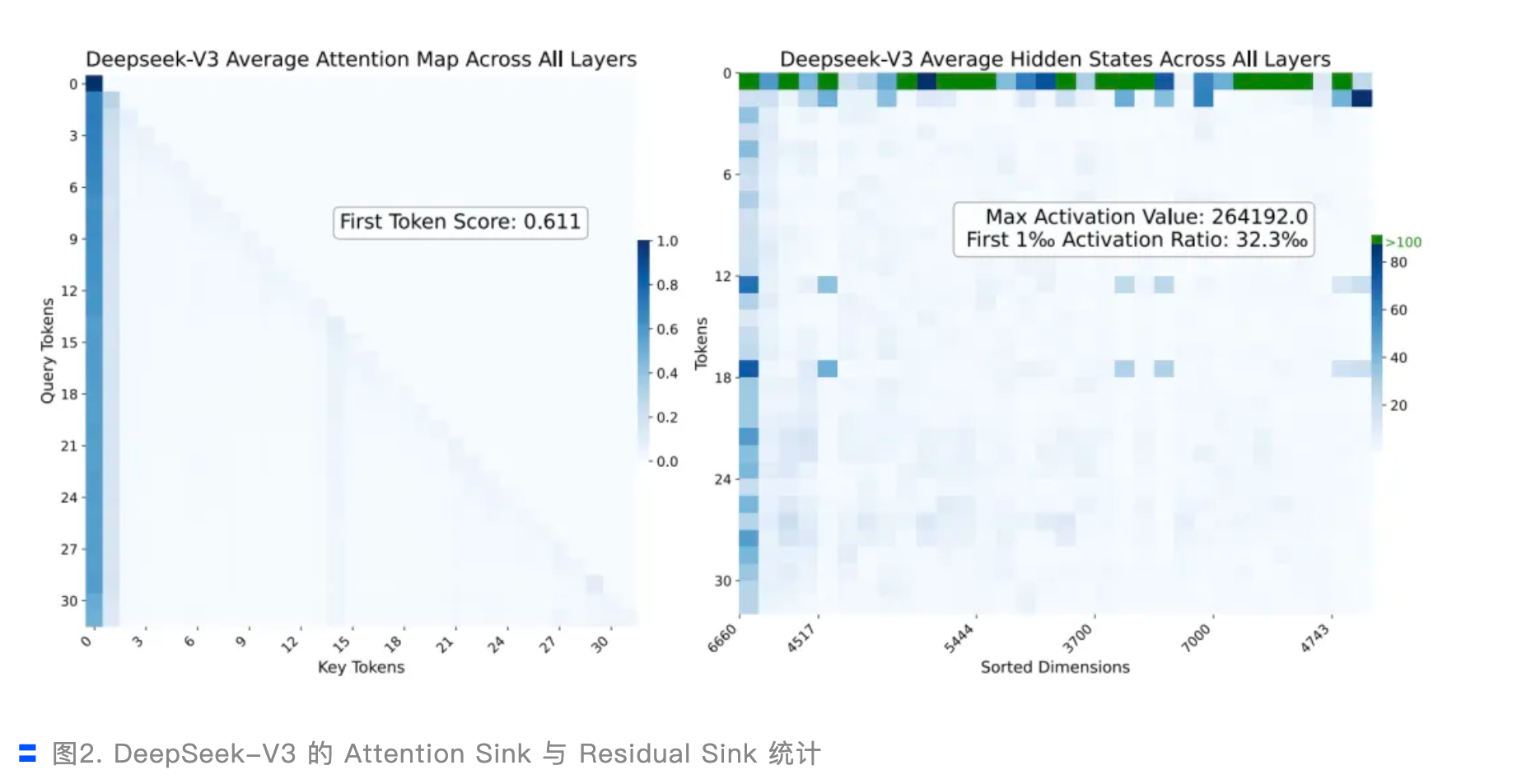
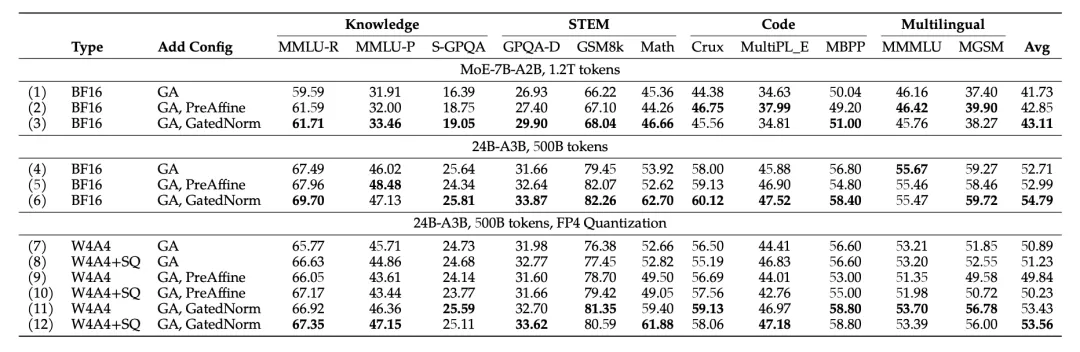
重点:提出了 GatedNorm来优化RMSNorm。动机是发现网络中会有很多极大的激活(原因是来自于RMSNorm的机制)。GatedNorm可以一定程度上稳定激活,提升量化精度(因为极大的激活就会造成量化的困难)同时侧面解释了为什么SwiGLU的表现通常要比GLU好。
- 异常激活很普遍,但是对于量化就很不友好了,例如下面的deepseekv3
- RMSNorm 的数学本质:
将token的除以它的能量(平方和),所以为了让整体norm,模型学会了让某几个激活值很大,这样分母就可以很大了,导致整体被除了之后,就比较小
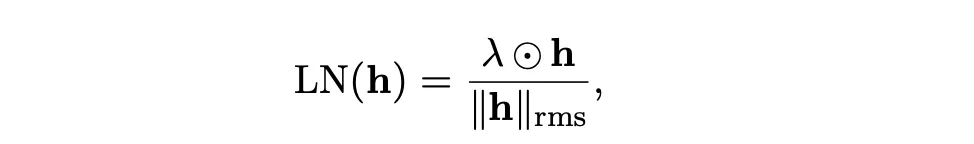
- 同时这也可能解释了SwiGLU的优势来源:
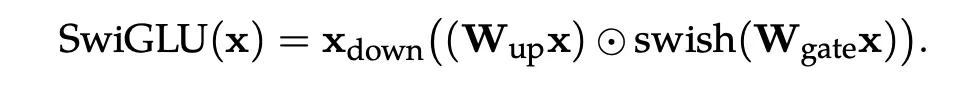
由于SwiGLU 使用的 Swish 激活函数在正半轴无上界,允许模型轻松生成巨大的异常值来触发 Rescaling。而标准 GLU 使用 Sigmoid,值域受限于 (0, 1),限制了这种自适应缩放的能力。
- 实验证明:Clipping,移除 RMSNorm,都会导致性能显著下降
- 解决方案:GatedNorm:
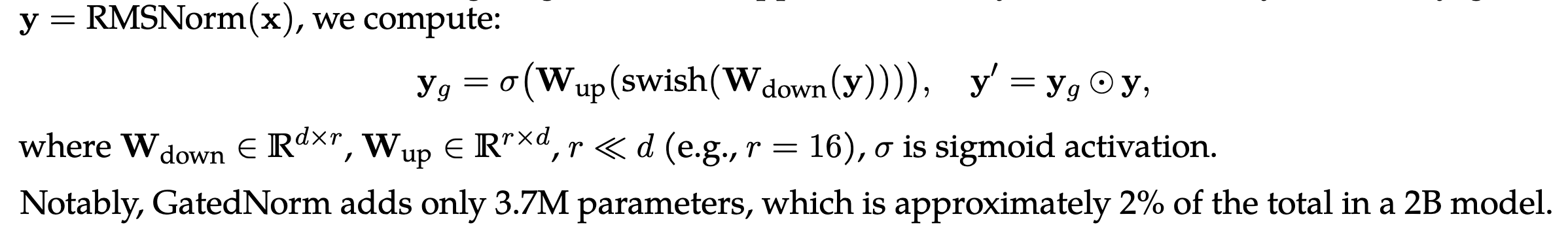
- 结果:
- 使用 GLU + GA + GatedNorm 的时候 要比 SwiGLU + GA + GatedNorm 好,loss更低,outlier也更少
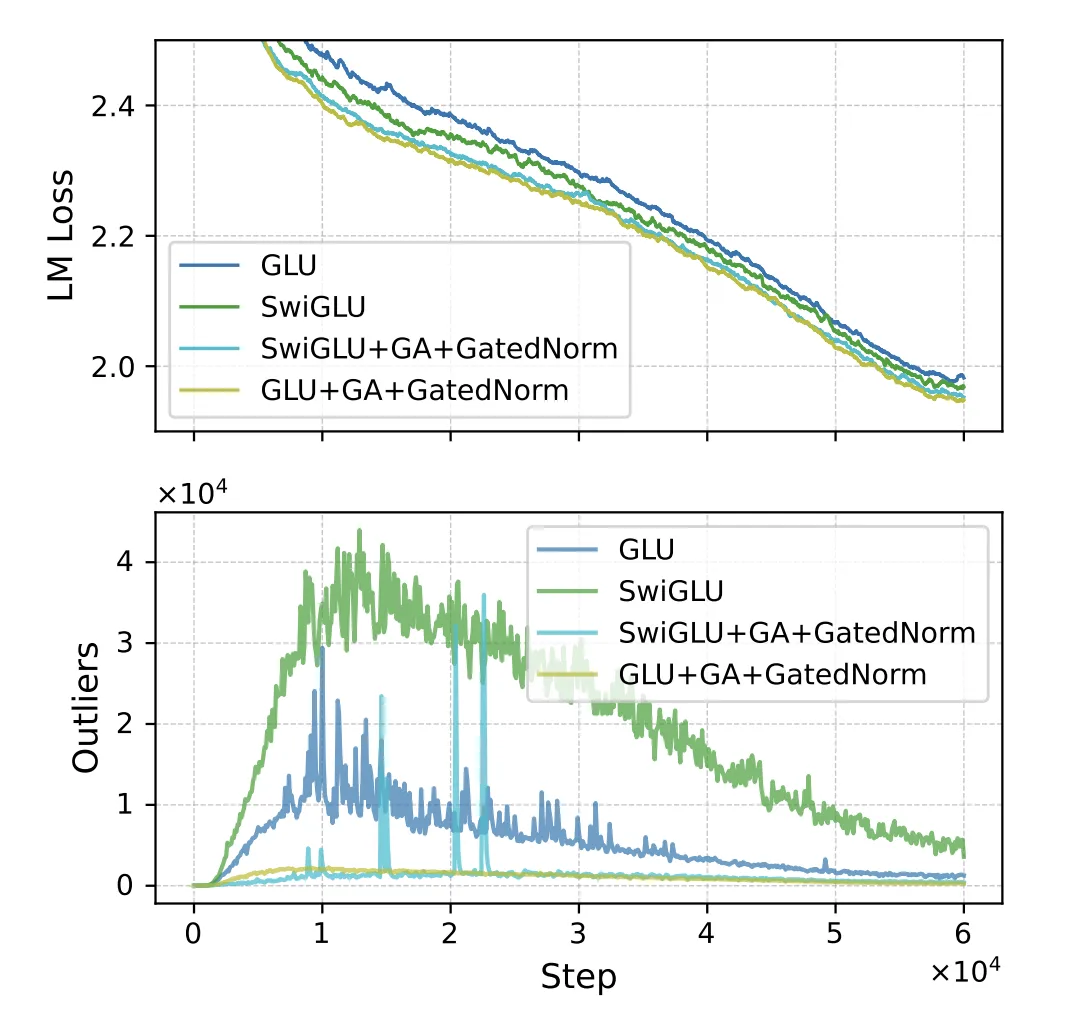
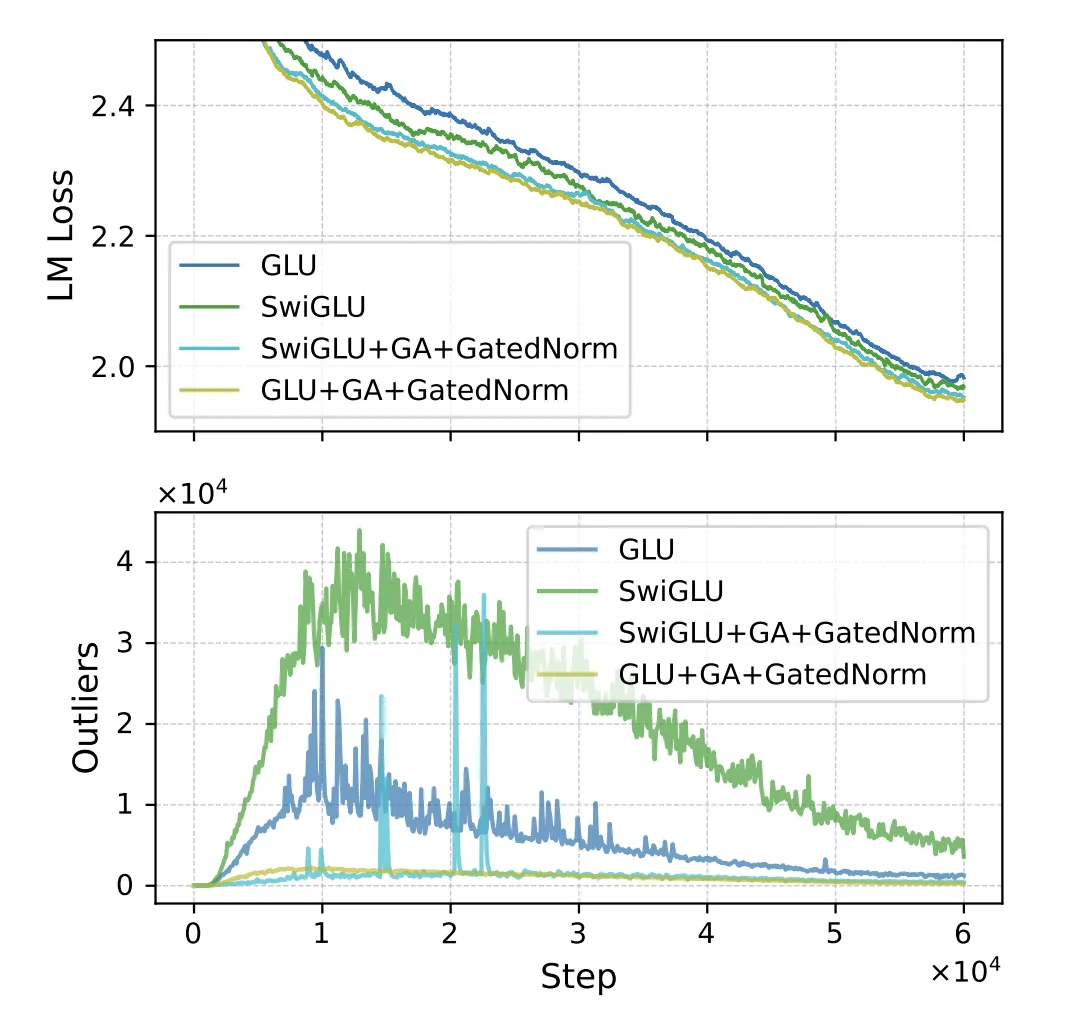
同时,在低比特量化的时候,+ GatedNorm 表现也更好:
BaseCV
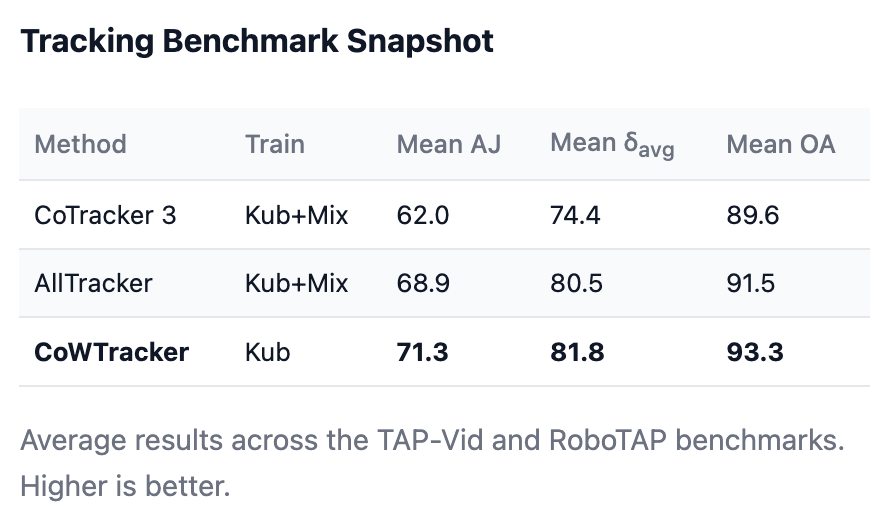
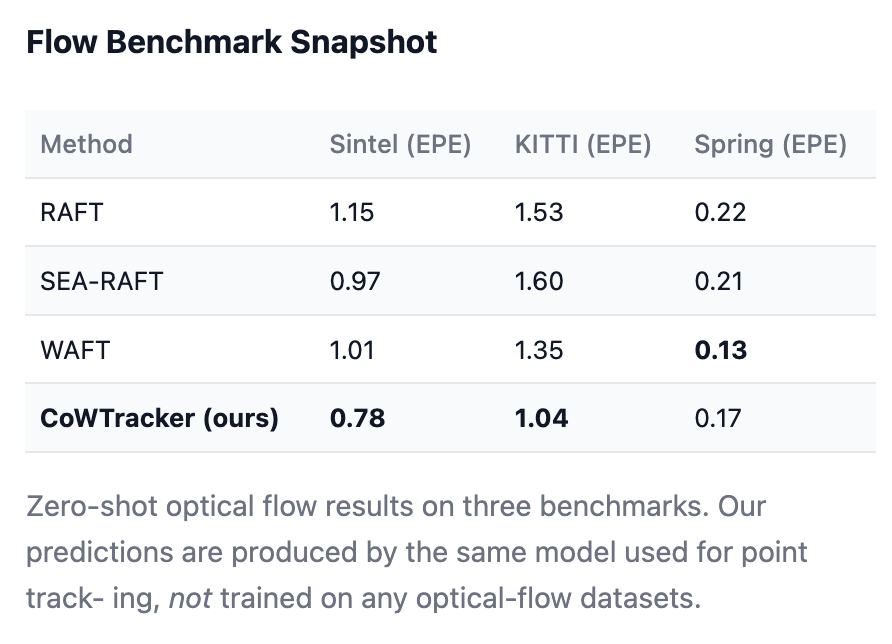
a. CoWTracker: Tracking by Warping instead of Correlation https://cowtracker.github.io/
机构:VGG
TLDR:舍弃了Cost Volumes,采用了Iterative Warping机制。不再全局搜索,而是根据当前的运动估计,直接在目标帧提取一个匹配点,然后不断微调。省去了昂贵的代价体积,可以处理极高分辨率的特征。
具体一点:
- Cost Volumes:第一帧中的某个点,在第二帧移动到了哪里?
- 代价体积是一个存储了“相似度分数”的巨大仓库。模型会提取两个图像帧的特征,然后计算一帧中每个像素与另一帧中候选区域内所有像素的相似度。
- 这种“暴力匹配”在数学上具有二次方复杂度。如果你想提高图像分辨率,计算量和内存占用会呈指数级爆炸。
- 位移场(Displacement Field):描述运动的语言
- 在 CoWTracker 中,追踪任务被定义为寻找一个位移场 u
- 假设视频中有一个查询帧 I0 和目标帧 It。对于查询帧中的任意一点 p,它在 t 时刻的新位置 xt(p) 可以表示为:xt(p)=p+ut(p) p 是该点最初的坐标,ut(p) 就是它这段时间的“移动向量”。
- Iterative Warping
- 不再去计算所有像素的相似度,而是基于当前的位移估计,直接从目标帧中“采样”特征,生成所谓的“扭曲特征图” Gt(p)
- Gt(p)=sample(Ft, p+ut(p)). Ft 是目标帧的原始特征,我们根据当前的位移估计 ut(p), 直接去那个位置提取特征
- 你不再对比人群里的每一个人,而是根据你的直觉(当前的位移估计)看向朋友可能出现的方向。如果你看歪了,模型会发现提取到的特征不对劲,然后通过迭代(反复微调)直到视野中心精准对准你的朋友。
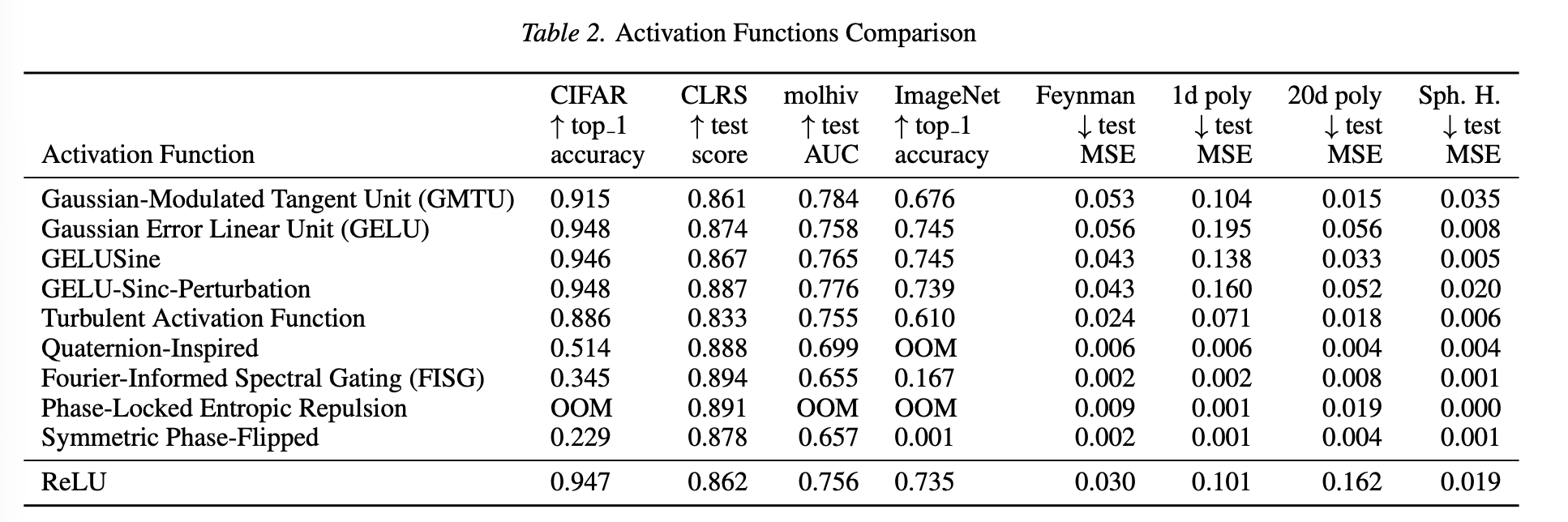
b. Mining Generalizable Activation Functions https://arxiv.org/abs/2602.05688
机构:DeepMind
TLDR:由 LLM 驱动的进化编码系统 AlphaEvolve 来搜索激活函数,在视觉任务上超过现有的激活函数
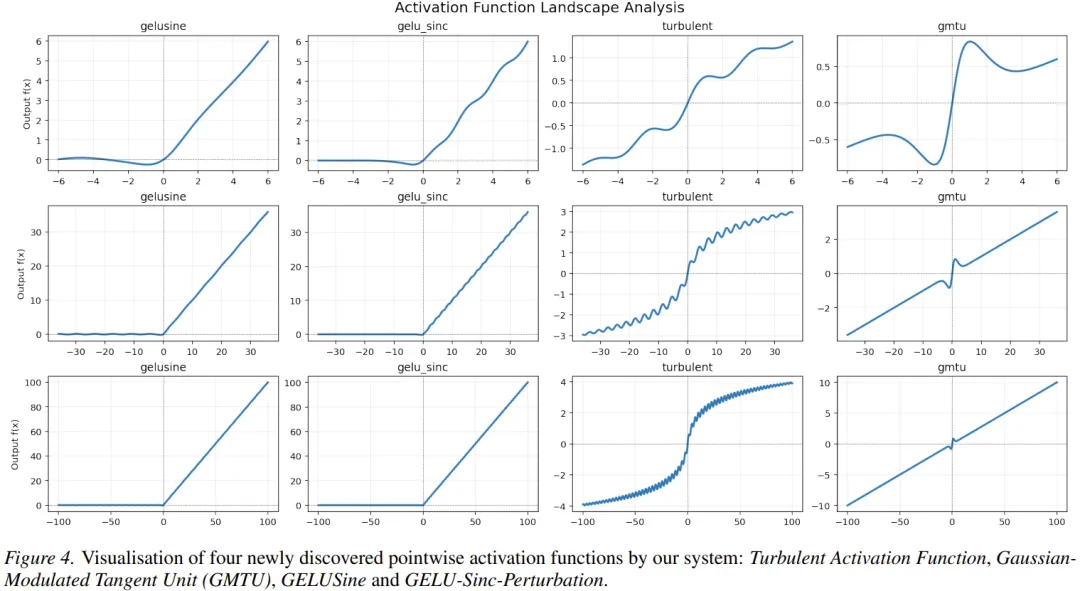
实验发现,表现好的函数往往遵循一个公式:
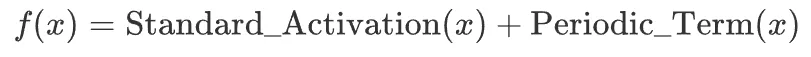
例如:
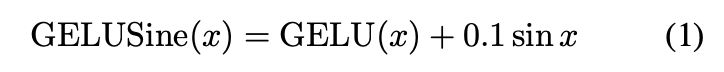
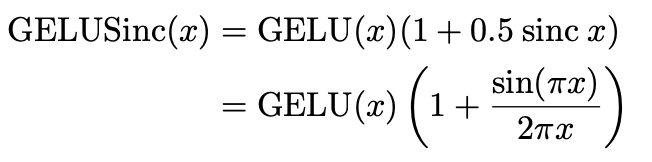
验证: