2.9-2.14
恭祝大家马年吉祥,万事如意!
目录:
- BaseCV
- Disentangle the class and patch token https://arxiv.org/pdf/2602.08626
- YoloMaster 2026.02 version update https://github.com/Tencent/YOLO-Master/releases/tag/YOLO-Master-v26.02
- VLM / LLM
- Zooming without Zooming https://arxiv.org/pdf/2602.11858
- Other things (won’t provide any comments but just an announcement)
- Qwen-Image-2 released
- SeeDance 2.0 released
- Veo 3.1 released
- FireRed-Image-Edit 小红书图像编辑模型 released
- 预计 Qwen3.5 和 DeepSeekv4 都将 release
BaseCV
a. ViT-5
机构:Johns Hopkins University,UC Santa Cruz.
TLDR:ViT-5 = 原始 ViT + 五年 Transformer 架构进化经验。And achieve SoTA
- LayerScale(激活缩放)
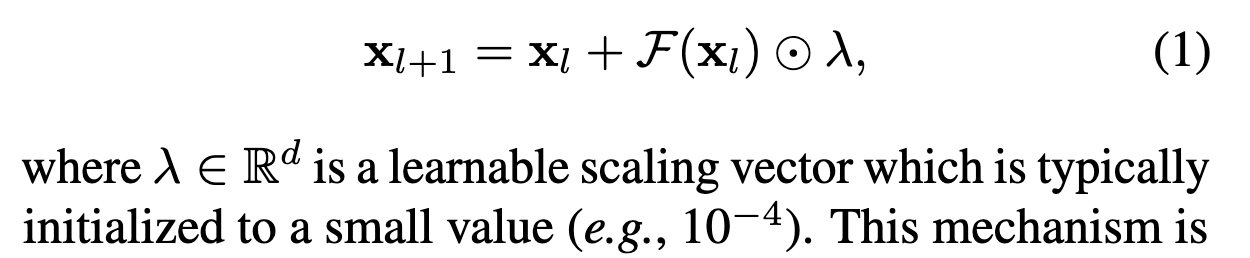
- RMSNorm(替代 LayerNorm)
- GeLU(保留,不用 SwiGLU)
- APE + 2D RoPE(双位置编码)
- Register Tokens(寄存 token)
- QK-Norm(Query/Key 归一化)
- 去掉 QKV bias
结果:
- APE + 2D RoPE(双位置编码):不同分辨率下结果更鲁棒
- QK-Norm:训练更稳定
- 分类分割生成 ViT-5 >> vanilla ViT and DeiT
b. Disentangle the class and patch token
机构:巴黎路桥,Meta
动机:"Despite the distinct nature of the [CLS] and patch tokens, current models treat them equivalently, applying the exact same operations to both.” 虽然它们在同一个数学空间里运算,但它们的功能定位完全不同,强行一致化会导致局部特征的丢失,甚至在注意力图中产生奇怪的“伪影”
发现:即便我们没有明确指令,模型内部的归一化层(LayerNorm)已经在自发地区分这两类信息了:LayerNorm 在进入注意力机制之前,会剧烈降低 [CLS] 和 Patch 之间的余弦相似度,使其几乎接近于零。某个维度可能专门被 Patch 占用,而 [CLS] 在该维度上几乎没有响应。这种维度的剥离,使得归一化层能够对它们执行截然不同的仿射变换。
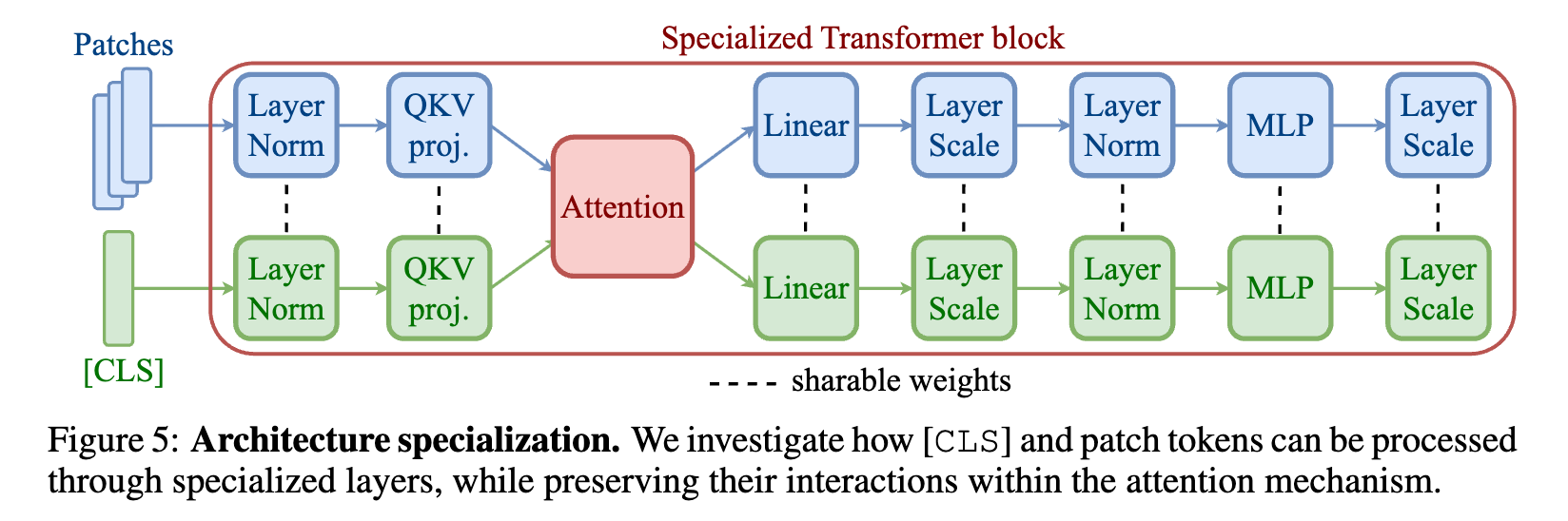
方法:
- 第一步:解耦处理路径。不要让
[CLS]和Patch共享所有的权重。为它们分别准备两套独立的参数,尤其是在归一化层(LayerNorm)和早期的 QKV 投影层(Query-Key-Value projections)
- 第二步:精准打击关键块。实验证明,不需要对模型的所有层进行改动。最有效的做法是只专业化模型前 1/3 的 Transformer 块。因为这是输入分布差异最大、认知冲突最剧烈的地方。
- 第三步:保留交互,分化处理。虽然处理路径分开了,但在注意力(Attention)机制中,它们仍然需要相互交流,维持信息的全局流转。
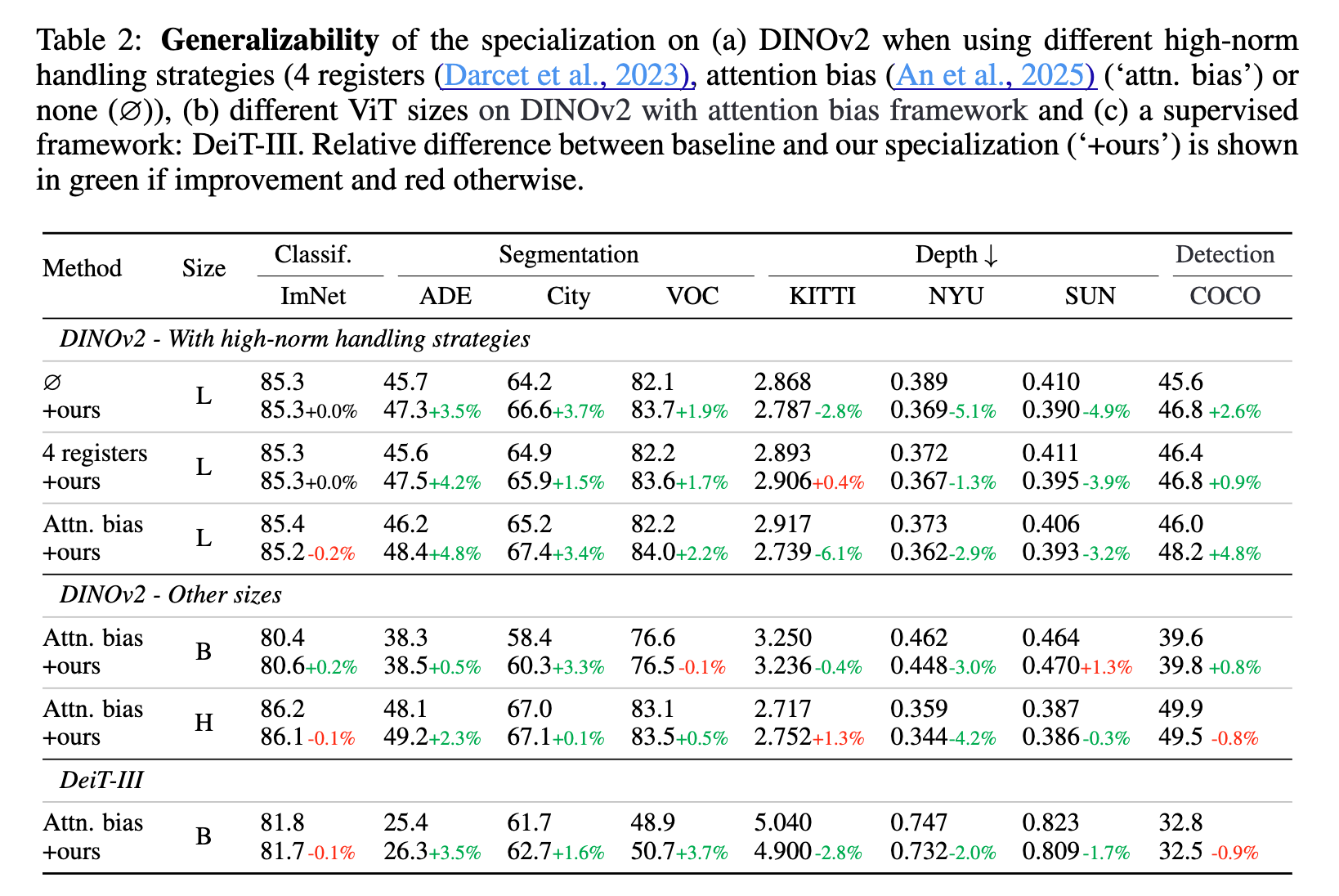
结果:在不同的ViT架构上,在 both dense(分割,单目深度估计和检测)和 classification 任务上,都有所提升,且没有额外flops的消耗。
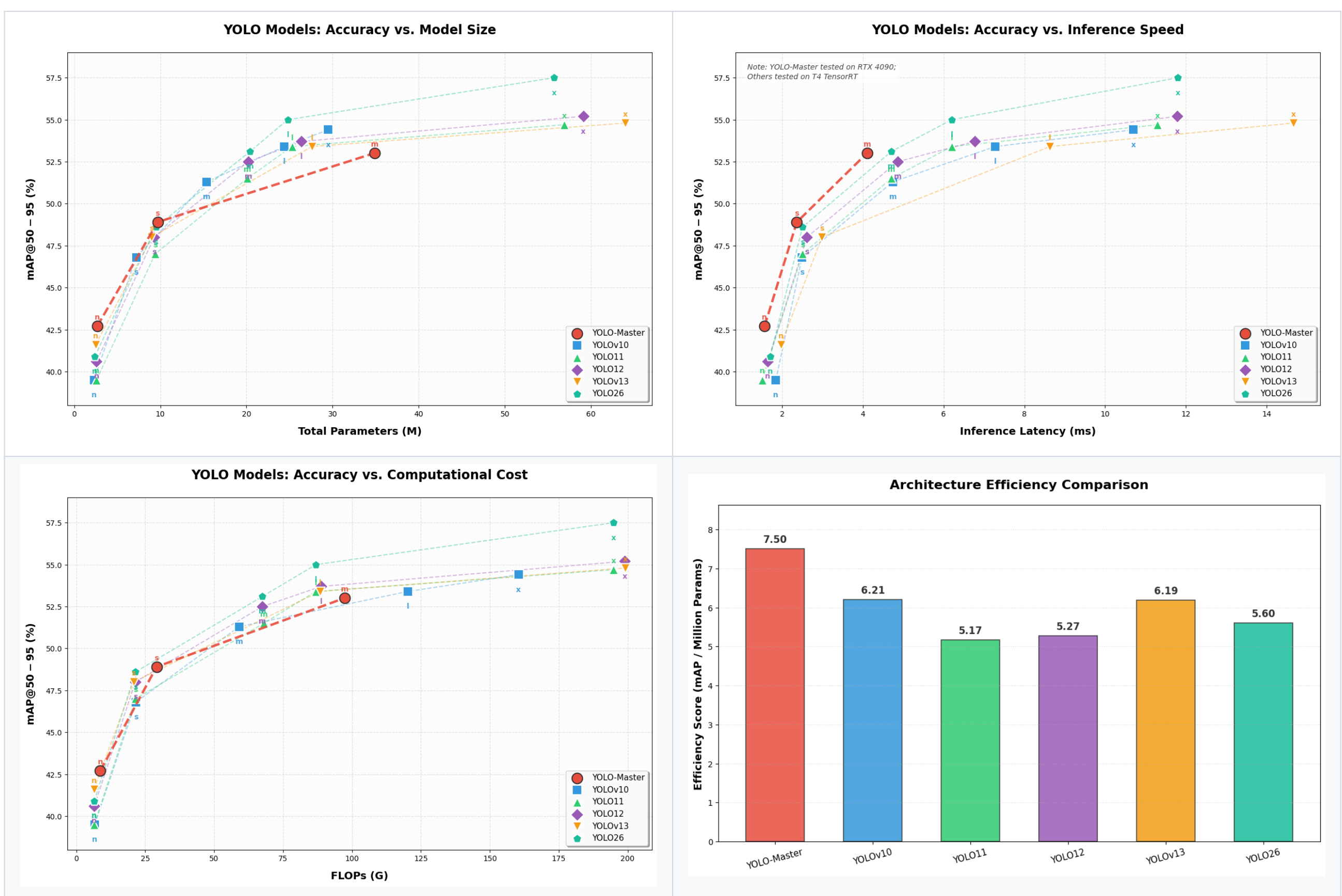
YOLO-Master v26.02
机构:腾讯优图
Still in progress
看上去在latency上比较有优势,在参数量和flops上表现一般。新提出的一些内容(Sparse SAHI Mode 与 Cluster-Weighted NMS (CW-NMS))可能对高分辨率输入与密集场景的检测的精度和效率有所帮助。
VLM / LLM
a. Zooming without Zooming: Region-to-Image Distillation for
Fine-Grained Multimodal Perception
机构:蚂蚁,上交
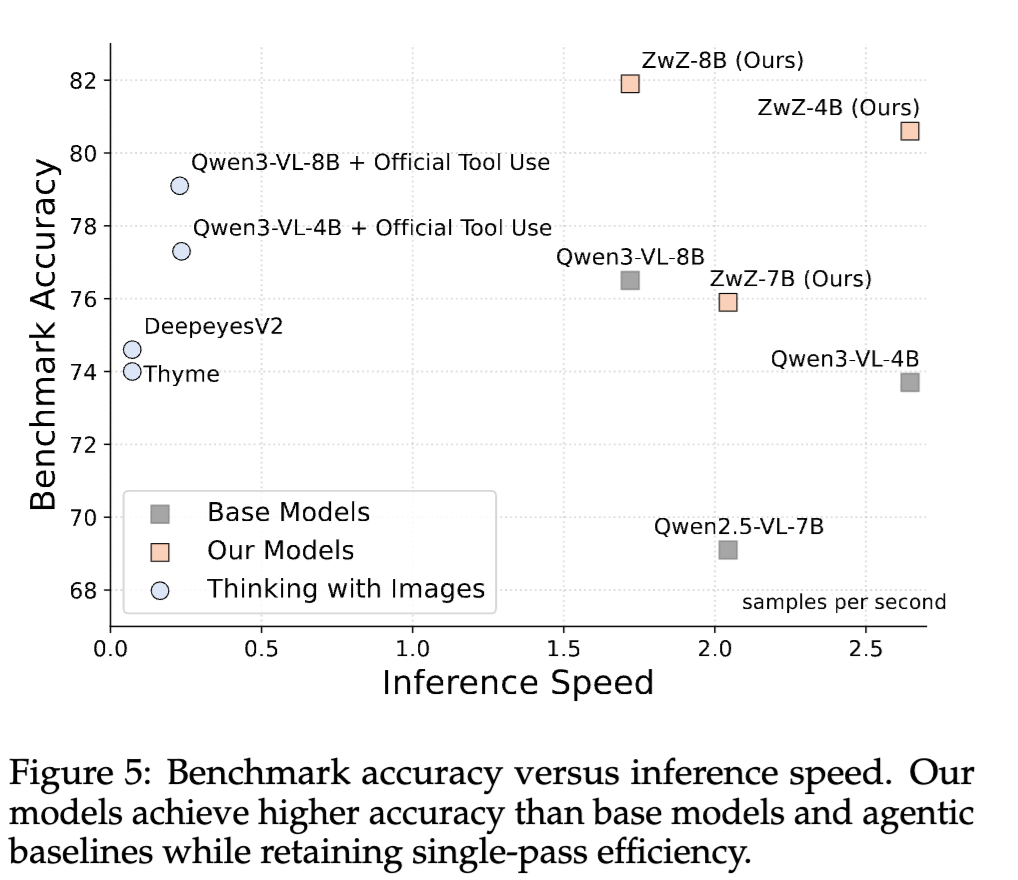
TLDR - result:仅有 80 亿参数的 ZwZ-8B 在多个细粒度感知榜单上,不仅大幅超越了同尺寸基座模型,甚至与参数量大其 30 倍的“巨无霸”(如 235B 的 Qwen3-VL 或 Kimi-K2.5)不相上下,并在某些指标上逼近了 Gemini-3 等顶级闭源模型。在处理 4K 高清图像时,ZwZ 模型比传统工具调用方法快了约 10 倍,且精度更高。
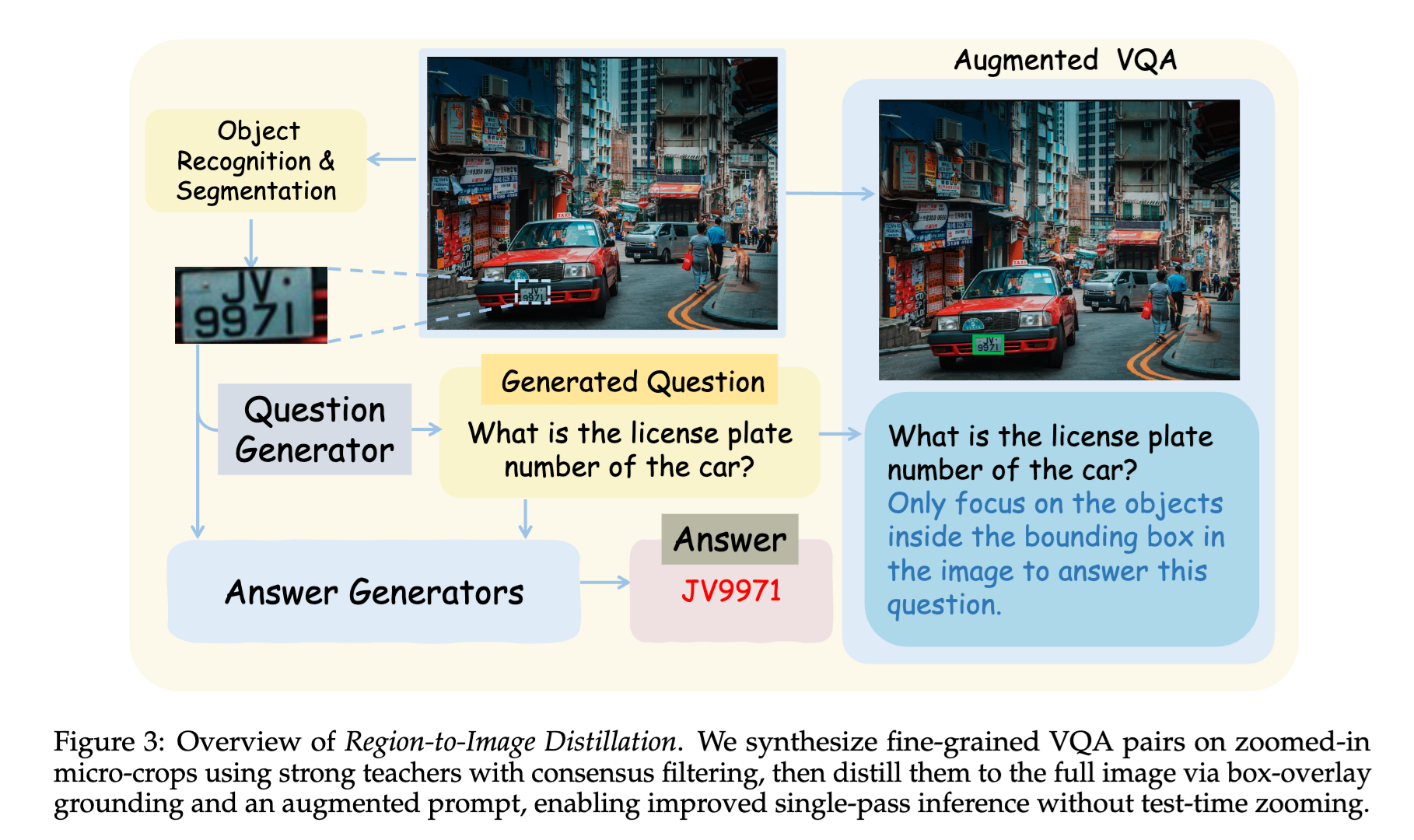
TLDR - method and eval:
- 如何炼就“意念放大”的视觉直觉?为了让 AI 形成这种本能,ZwZ 采用了一种系统化的 区域到图像(Region-to-Image, R2I)蒸馏方法。以下是其实施的具体步骤:
- 目标驱动的“缩放”合成:首先利用目标检测系统从大图 I 中识别出有意义的微小区域 R(如车牌、仪表盘),要求该区域面积占比小于 0.1。
- 专家授课与共识过滤:调用云端超大模型(老师)仅针对清晰的局部区域 R 生成问答对。为了确保绝对真实,采用多个老师“投票制”,只有当 8 票中获得 6 票以上一致性时才保留该数据,从而彻底消除幻觉。
- 视觉锚定蒸馏:将局部答案对应回原始大图 I。为了解决位置歧义,在训练阶段将边界框(Bounding Box)直接叠加在图像上作为“特权信息”。
- 强化学习内化:使用 DAPO(低秩自适应偏好优化) 算法进行训练,利用可验证的奖励机制(如规则匹配和连续计数奖励)强迫学生模型在全局视野下寻找微观证据。
通过这种方式,模型在训练时学会了“盯着看”,而在实际测试中即使没有边界框引导,它也会自动将注意力集中在关键区域。
- 研究者提出了一个有趣的衡量指标:缩放差距(Zooming Gap)。即模型在“看全图”和“看切片”时表现出的性能差。传统模型在看到全图时,注意力会被海量的背景信息稀释。ZwZ 通过分析模型的相对注意力覆盖率(Relative-Attention Coverage Ratio),量化了这一改进:
公式中的 Arel 代表与问题高度相关的注意力分布。实验证明,ZwZ 模型在关键区域的注意力集中度显著提升。它成功将 Qwen3-VL-8B 原本 25.21% 的“缩放差距”大幅缩减至 15.26%,这是目前所有测试模型中最小的缺口。