2.15-2.26
恭祝大家马年吉祥,万事如意!
目录:
- BaseCV
- Le-DETR: Revisiting Real-Time Detection Transformer with Efficient Encoder Design https://arxiv.org/pdf/2602.21010
- RaCo: Ranking and Covariance for Practical Learned Keypoints https://arxiv.org/pdf/2602.15755
- On Surprising Effectiveness of Masking Updates in Adaptive Optimizers https://arxiv.org/pdf/2602.15322v1
- Taming SAM3 in the Wild: A Concept Bank for Open-Vocabulary Segmentation https://arxiv.org/pdf/2602.06333
- SAM 3D Body https://arxiv.org/abs/2602.15989
- Xray-Visual Models: Scaling Vision models on Industry Scale Data https://arxiv.org/pdf/2602.16918v1
- VLM / LLM / GenAI
- BitDance: Scaling Autoregressive Generative Models with Binary Tokens https://arxiv.org/abs/2602.14041
- Pailitao-VL https://arxiv.org/abs/2602.13704v1
- Other things (won’t provide any comments but just an announcement)
- 阿里发布 Qwen3.5 系列模型
- Kimi 上线 Kimi Claw(但仅限高级付费用户使用)
- Minimax 上线 MaxClaw
- Lyria 3 (by Google)released:30-second tracks using text or images 音乐生成
- Adobe release Object-WIPER (很炫酷demo的 video object removal 工作)https://sakshamsingh1.github.io/object_wiper_webpage/
- 小红书发布的视频创作智能体框架 OpenStoryLine https://fireredteam.github.io/demos/firered_openstoryline/
- 小红书开源 SOTA OCR 模型 dots.ocr-1.5 ,并能将图表和示意图直接转换为 SVG 代码 https://github.com/rednote-hilab/dots.ocr
- 阿里开源全新的原生多平台 GUI 代理基础模型系列 GUI-Owl 1.5 (2B/4B/8B/32B/235B;指令与思考)。该新一代原生 GUI 代理模型系列基于 Qwen3-VL 构建,支持桌面/移动/浏览器自动化,并在 20 多个 GUI 基准测试中取得了SOTA 性能
BaseCV
a. Le-DETR: Revisiting Real-Time Detection Transformer with Efficient Encoder Design https://arxiv.org/pdf/2602.21010
机构:SHI Labs @ Georgia Tech
TLDR:Le-DETR 是一个在latency上比较有优势的模型,主要的 contribution 是提出了一个新的backbone 来替代 hgnetv2。可以用更少的公开数据(ImageNet1K)进行预训练,得到更好的结果
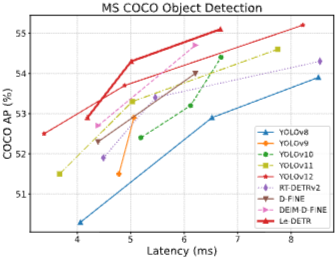
方法:
- backbone:
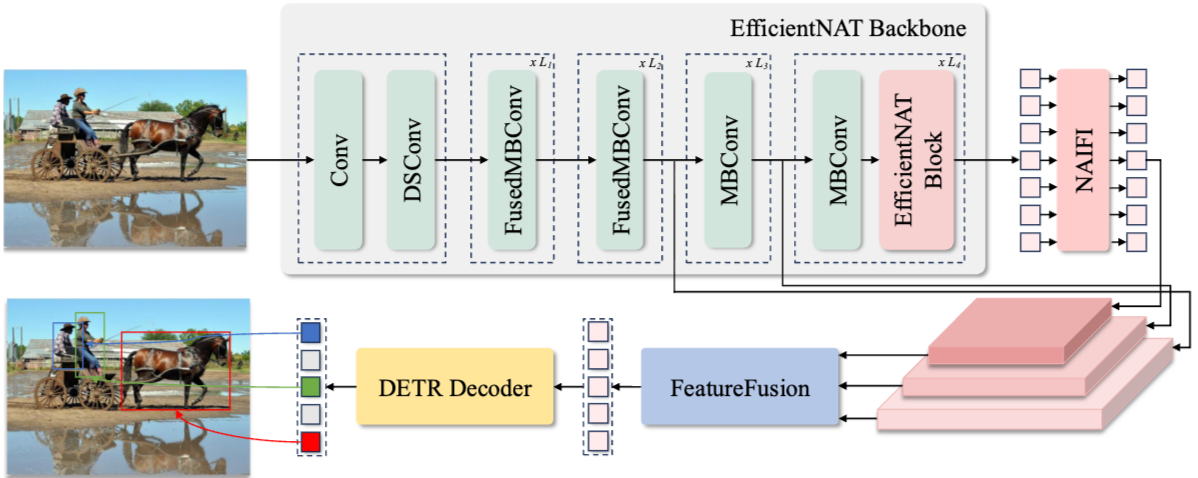
EfficientNAT = Conv + depthwise separable convolutions (DSConv) + Fused Mobile Convolution (FusedMBConv) + Mobile Convolution (MBConv) + EfficientNATBlock + NAIFI
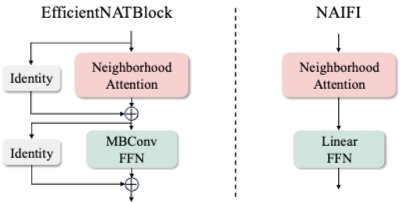
其中,NAIFI 就是 NAT+FFN,EfficientNATBlock 就是 residual NAT + residual MBConv
- Detector
Detector部分没有什么特别,除了训练的时候用6层,推理的时候用4层来加速减参数之外。
- 其他:
- Insight还是有的,即一个共识 backbone is all you need
- 有一些好奇,例如:6层训练4层推理,会不会比4层训练4层推理更好?训练的hyperparameters有没有必要进行一些调整?backbone的variants实验中使用top1 acc/top5 acc并没有详细说明是什么acc,默认是分类的acc的话,分类acc上的结论在detection上也work吗?
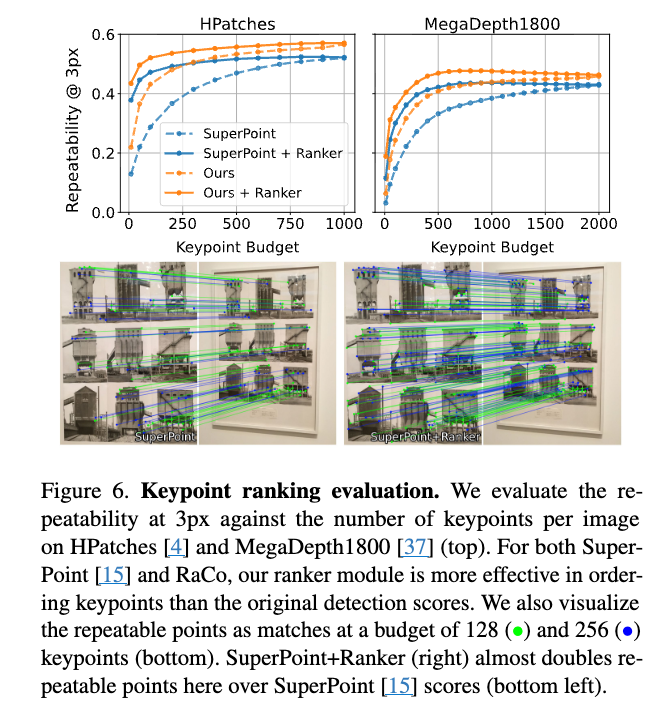
b. RaCo: Ranking and Covariance for Practical Learned Keypoints https://arxiv.org/pdf/2602.15755
机构:ETH,Google,Microsoft
TLDR:RaCo 是一个轻量级神经网络,集成了可重复关键点检测器、可微分排序器和协方差估计器,旨在学习稳健且多功能的关键点。该模型通过广泛的数据增强实现了强大的旋转鲁棒性,无需昂贵的等变网络,并能有效学习关键点排序以最大限度地提高匹配度,同时预测度量空间不确定性。实验结果表明,RaCo在关键点重复性和双视图匹配方面达到了 SOTA,尤其是在大平面旋转下,其协方差估计也显著提高了3D三角测量任务的准确性。
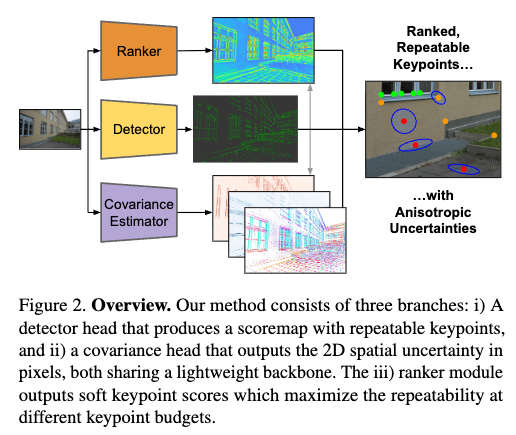
方法:
RaCo = a Detector to find repeatable keypoints + a differentiable Ranker to maximize repeatability at smaller keypoint budgets + a Covariance estimator to quantify their spatial uncertainty
- Keypoint Detector:旨在识别在多视角和不同外观条件下可以可靠、准确地检测到的关键点,通常位于角点或斑点区域。
- 具体地,接收归一化的 RGB 图像 I,输出一个关键点分数图 S \in R^{H \times W}。通过对 进行全局 softmax 操作,得到像素作为关键点的概率图 P \in R^{H \times W}。关键点 x_v \in R^{N \times 2} 通过在概率图上应用非极大值抑制 (NMS) 和 Top-N 选择来提取。
- 旋转鲁棒性来自训练中广泛的数据增强,具体地,训练对是通过合成单应性变换和强光度变换生成,包含完整的 360 度旋转。
- 训练:policy-gradient 。对于视图A中的关键点x,如果其在视图B上重投影的关键点,与视图B中最近邻关键点的距离,小于一个值,则是正奖励,否则为负奖励,奖励记为 \rho,这个奖励会在损失计算的时候,进行归一化。训练的损失,是最小化采样关键点的负对数似然。其中,p 是从概率图 P 中采样的 sampling probability of keypoint x。
- 可微分排序器 (Differentiable Ranker):提供一种替代的排序方式,专门设计用于在不同关键点总数下最大化匹配的点数。

具体来说,就是找到一个很好的排序分数 r 的表示器或排序图 R,让 M 越大越好(其中 n 是 n 个检测到的关键点,k 是 k 个匹配上的点)。但是上面的 M 不可微,所以我们需要学一个排序图 R \in R^{H*W}: h 是一个 ranking operator (n→n),将ranking scores r 转为可微的 r_soft
- Covariance estimator 协方差估计器:协方差头预测的是每个特征点的 2D 像素级不确定性。
实际上就是用 NLL 对重投影误差进行拟合:
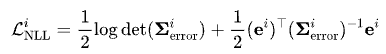
RaCo模型在通过合成图像对进行训练,这些合成图像对是从 Oxford-Paris 1M distractors dataset 中采样生成的。它通过从现有图像中采样两个裁剪区域,并应用合成单应性变换(2D-2D变换 x2=Hx1)以及强光度增强来模拟双视角匹配,从而进行自监督训练。
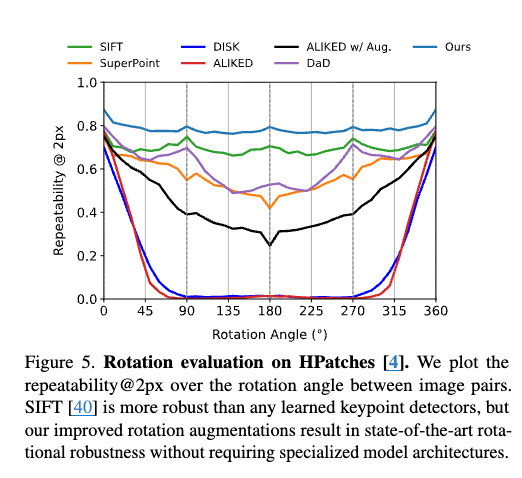
从结果上看,角点在旋转的情况下的检测“重复率”,即能够重复被检测出来的比例是最高的,优于 SIFT。同时在使用较少角点budget的情况下的结果也是相当好的。同时在其他的定量指标上也基本上都是 SOTA。
c. Magma - On Surprising Effectiveness of Masking Updates in Adaptive Optimizers https://arxiv.org/pdf/2602.15322v1
机构:Google
TLDR:训练大模型时随机跳过50%的参数更新(SkipUpdate) + 动量-梯度对齐分数 = Magma。Magma 在 1B 模型上比 Adam 降低19% 困惑度,比 Muon 降低9% 困惑度。

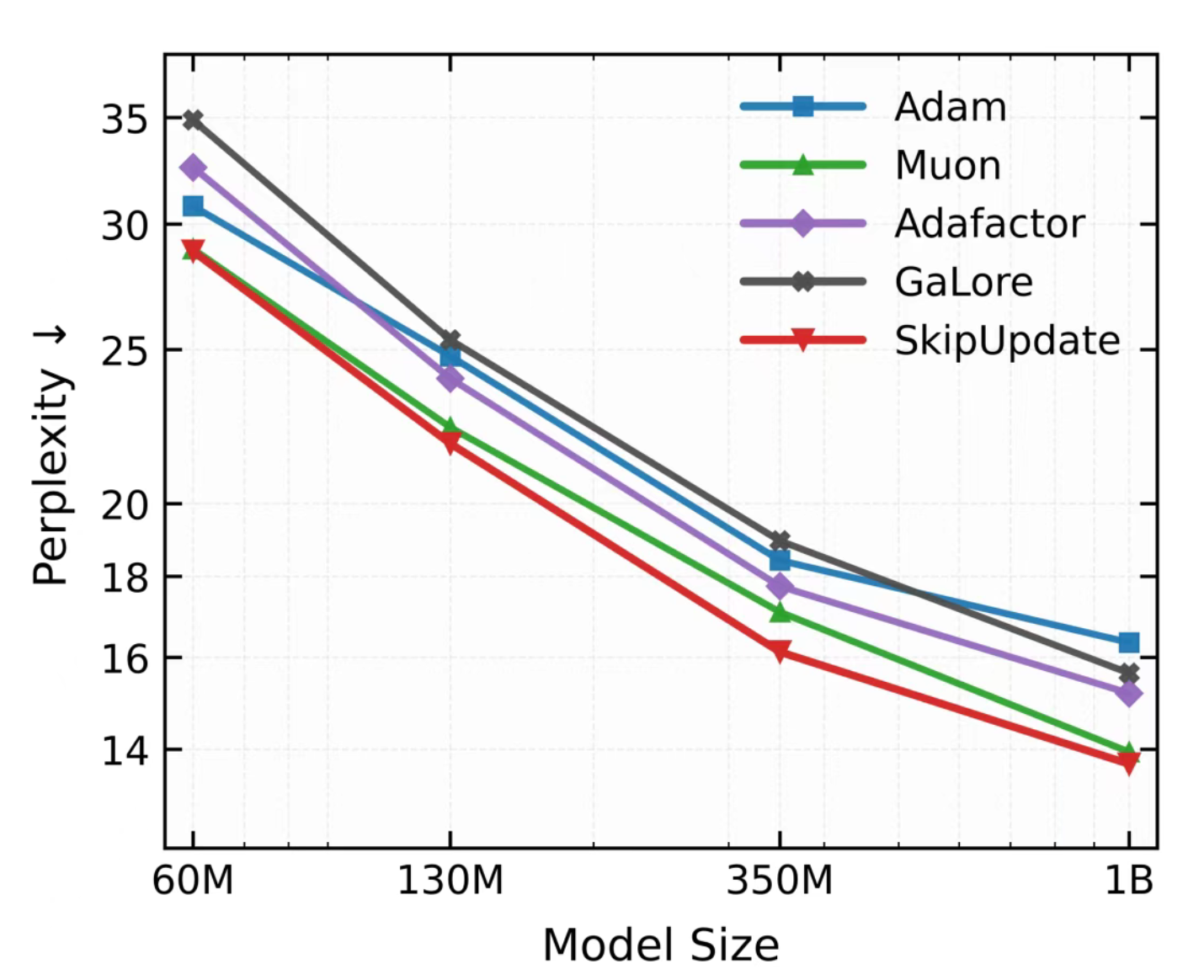
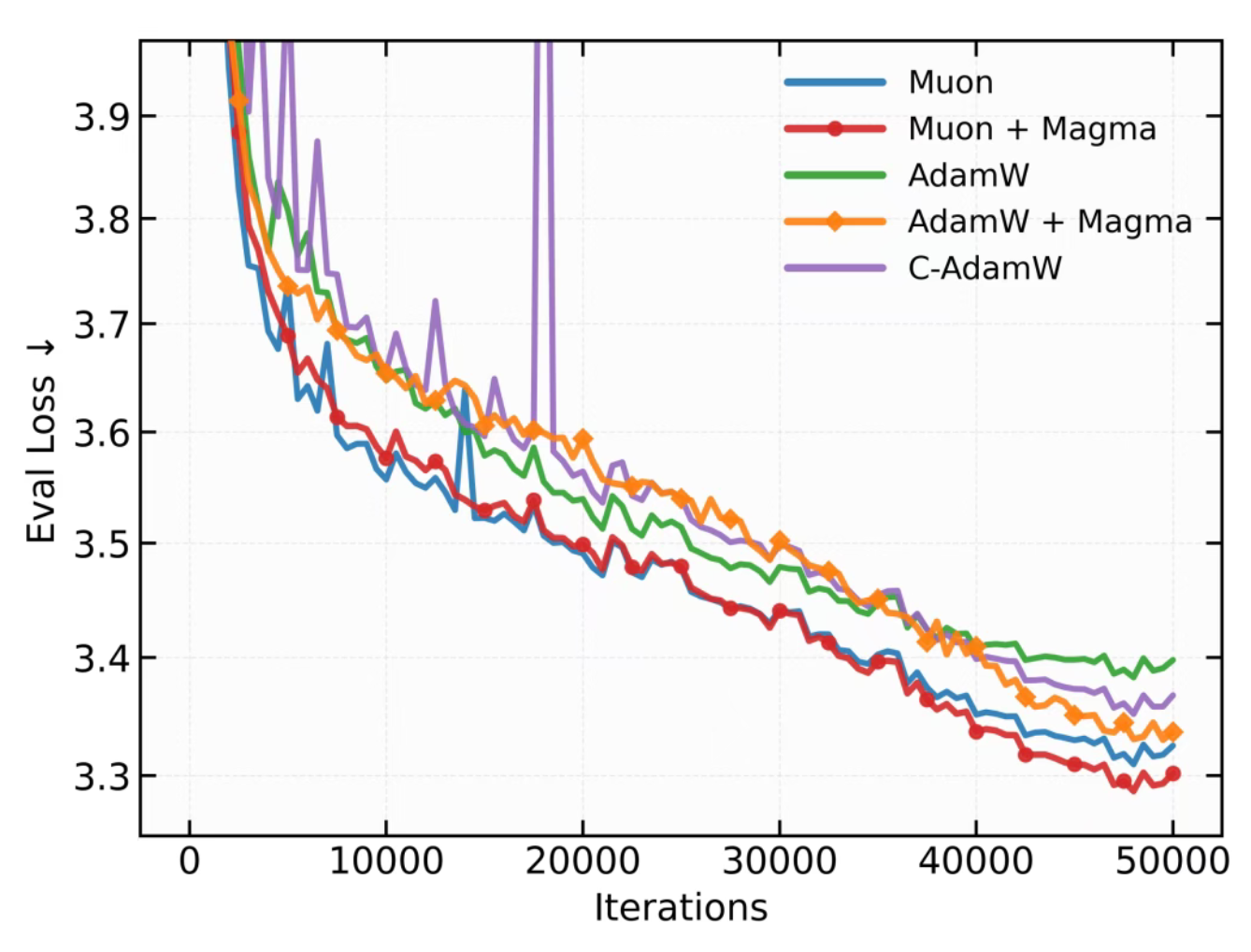
发现:
- SkipUpdate,这是一种在每个迭代中随机 block-wise masking 的策略,遵循伯努利分布。SkipUpdate 在期望损失中隐式引入了一项曲率相关的正则项,优化轨迹被推向损失landscape 平坦区域,类似 SAM 。当一个块被mask的时候,其参数更新被跳过,但是动量估计会被更新。未被mask的部分的参数更新会进行重新缩放(类似dropout)。
- Magma(Momentum-aligned gradient masking),通过利用随机梯度与一阶动量估计之间的余弦相似度(cosine similarity)来调制掩蔽更新。如果当前梯度和历史动量方向一致(cosine similarity 高),说明这是一个可靠的优化信号;如果方向矛盾,大概率是噪声在捣乱。
实验结果: 实验涵盖了Llama模型在C4数据集上的预训练(模型规模从60M到1B)、Nano MoE模型在OpenWebText上的预训练,以及在受控重尾梯度噪声和异构二次函数上的基准测试。实验表明,训练更加稳定,同时取得了最低的困惑度。
d. Taming SAM3 in the Wild: A Concept Bank for Open-Vocabulary Segmentation https://arxiv.org/pdf/2602.06333
机构:一堆
TLDR:针对 SAM3 在跨域推理时因 distribution shift 导致的对齐失效问题,提出了一种无参数的概念库(ConceptBank)校准框架,动态重构目标域的文本锚点以恢复视觉与文本的匹配。结果看上去很不错,同时 这个工作和 https://intellindust-ai-lab.github.io/projects/FSOD-VFM/ 有相似之处。
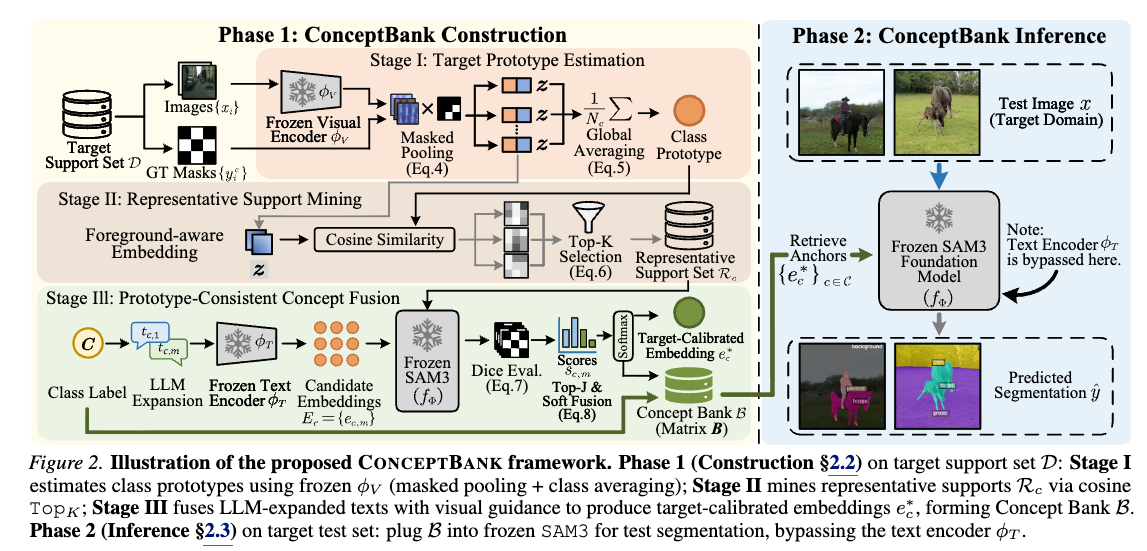
方法:
以一个类为例:
- 根据 support set gt 得到 object 的 prototype feature
- 利用 prototype 与 object feature 做比对,筛出最具代表性的 support set 中的样本(crops+label pairs)
- 利用 LLM 对 这个类别的 text 进行增强
- 利用 这个类别增强的 text + 代表性 support set 中的样本,通过sam3进行 segmentation,得到不同 text 的 Dice score
- 对 Dice score 进行归一化,分配给 text embedding 再进行求和(一个对于 多个 text embedding的加权和),得到这个类别的 增强版本 text representation,即为 Concept Bank B中概类别的表征
- 在推理的时候,使用 B 中的 text embedding 进行推理。
从结果上来看,基于 SAM3 的提升是很明显的。
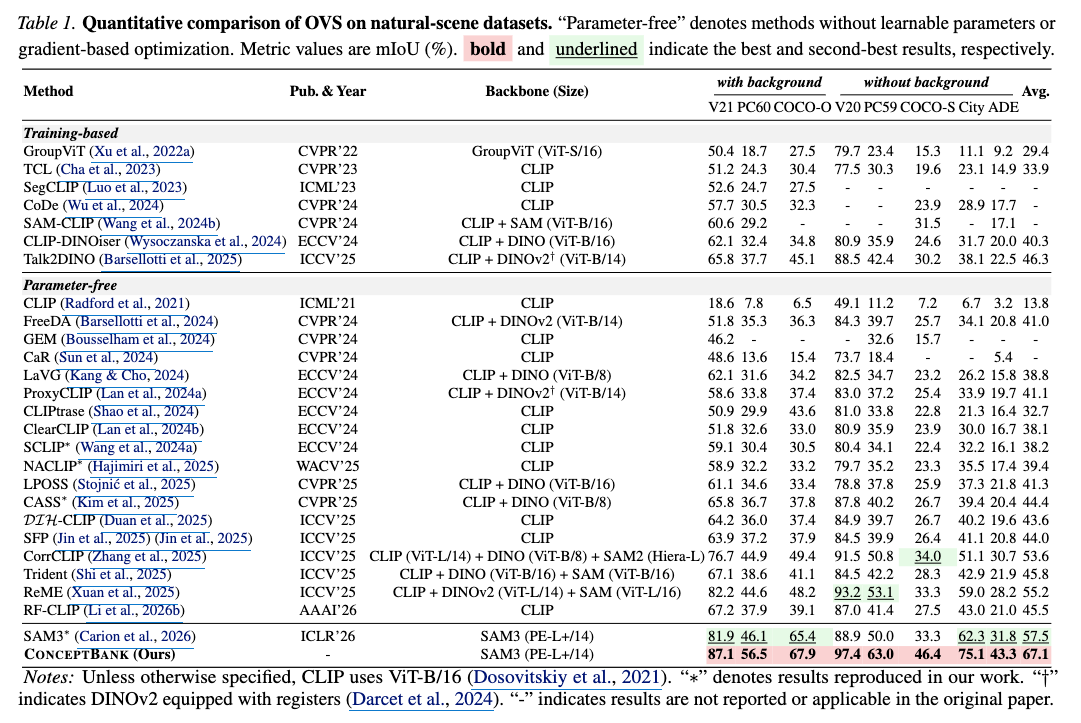
这算是利用 few-shot 进行 prompt engineering 的工作,也有很多此前一些见过工作的影子,尤其是利用 llm 进行 enhance,以及加权和等操作。