2.27-3.7
目录:
- BaseCV
- Accurate Planar Tracking With Robust Re-Detection https://cmp.felk.cvut.cz/~serycjon/WOFTSAM/
- Synthetic Visual Genome 2: Extracting Large-scale Spatio-Temporal Scene Graphs from Videos https://arxiv.org/pdf/2602.23543
- VLM / LLM / GenAI
- Beyond Language Modeling: An Exploration of Multimodal Pretraining https://beyond-llms.github.io/
- CoPE-VideoLM: Codec Primitives For Efficient Video Language Models https://sayands.github.io/cope/
- SpatialLM: Training Large Language Models for Structured Indoor Modeling https://manycore-research.github.io/SpatialLM/
- BeautyGRPO: Aesthetic Alignment for Face Retouching via Dynamic Path Guidance and Fine-Grained Preference Modeling https://beautygrpo.github.io/
- Toward One Encoder for All Point Clouds https://pointcept.github.io/Utonia/
- Other things (won’t provide any comments but just an announcement)
- Qwen-Image-2.0-pro-260303 + Qwen-Image-2.0-260303 上线。(使用了后者,发现一股很浓的 seedream4.5 味(仅个人感受))
- LumaAI 提出 UNI-1 https://lumalabs.ai/uni-1 很牛很牛,去看网页里的demo吧!!
- Autoresearch by Andrej Karpathy: AutoML but in 2026 https://github.com/karpathy/autoresearch
a. Accurate Planar Tracking With Robust Re-Detection https://cmp.felk.cvut.cz/~serycjon/WOFTSAM/
机构:Czech Technical University in Prague(Jiri Matas)

以下大部分内容由 NoteBookLLM 生成
TLDR:
- 动机 / 发现:在过去,平面跟踪高度依赖物体的“纹理”,但是传统平面跟踪在模糊、遮挡和无纹理表面(如镜子)下极易失效。
- 改进 / 方法:结合 SAM 2 的分割能力,提出 SAM-H 几何重检测机制,并与基于光流的 WOFT 算法融合形成 WOFTSAM。
- 结果:在 POT-210 和 PlanarTrack 两个顶级测试集上刷新了纪录,尤其在复杂场景下性能提升巨大(+12.4~15.2%)。
方法:
- SAM 2 擅长分割,但它只提供一个模糊的遮挡块(Mask),并不懂精确的几何姿态。于是,SAM-H 应运而生:
- 从掩码到线条:利用 Hough 变换,从 SAM 2 生成的不规则掩码边缘中提取出四条最稳健的直线。
- 从线条到交点:通过这四条线的交点,重新找回物体的四个顶点。
- 身份识别(DINOv2):因为矩形具有对称性,算法必须搞清楚哪个点是左上角。研究者引入了 DINOv2 特征匹配,通过对比当前裁剪图与原始模板的特征,在 0.2 秒内就能锁定正确的旋转角度。
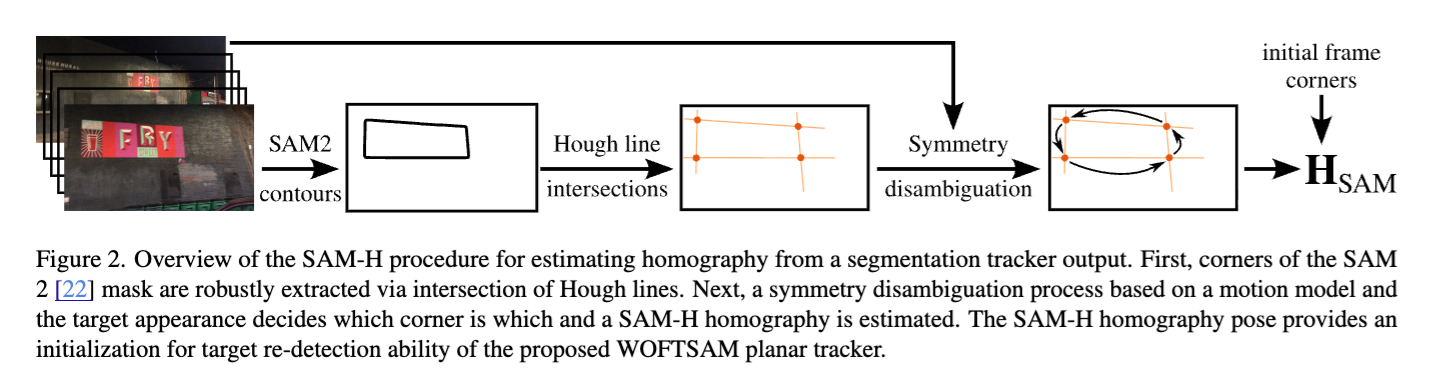
- WOFTSAM
单纯靠分割(SAM-H)虽然稳健,但在细节精度上不如基于光流(WOFT)的算法。WOFTSAM 的策略非常务实:它采用了一种双重尝试机制:
- 第一步(快速追踪):首先尝试用上一帧的姿态进行光流估计。如果成功(内点比例高),则皆大欢喜。
- 第二步(重检测):如果光流法失败(例如被遮挡后重新出现),则立刻启动 SAM-H 进行“全图搜索”和重检测。
这种互补性让它在面对极端情况时表现惊人。例如,在面对一面镜子时,光流法可能会被镜子里反射的墙壁纹理带偏,而 SAM-H 却能死死咬住镜框本身。
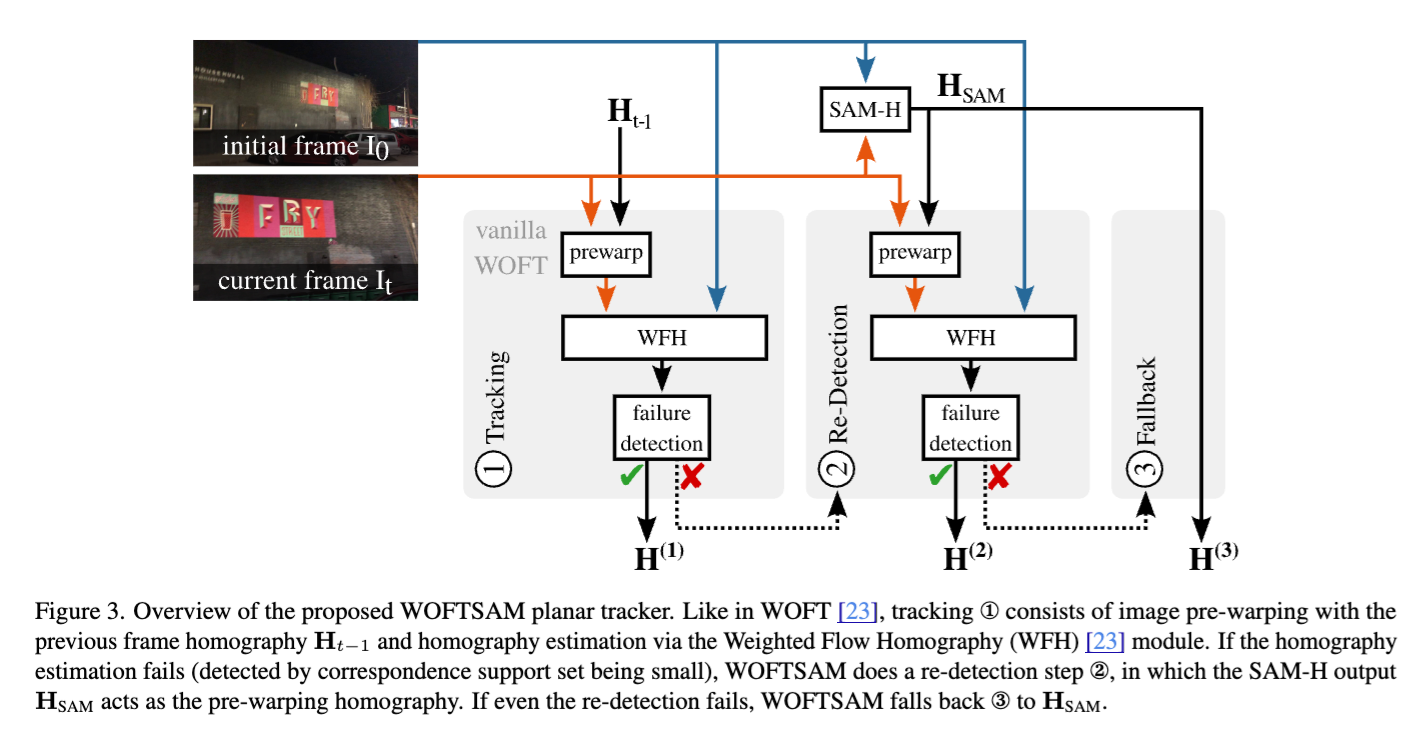
实施指南:
- 初始化:在视频第一帧手动标注目标的四个控制点 X0。
- 分割启动:将 X0 作为提示(Prompt)输入 SAM 2.1,获取每一帧的掩码 St。
- 几何提取:
- 丢弃长度小于 20px 的噪点轮廓。
- 对掩码边缘进行 Hough 投票,寻找 4 条峰值直线。
- 通过最小二乘法精修直线参数,并计算四个顶点交点。
- 姿态消歧:如果目标丢失后重现,提取当前区域的 DINOv2 特征,与初始模板进行四个角度的相似度比对,连续 5 帧一致则判定为重定位成功。
- 单点降级处理:如果只能看到两个点,退化为 4 自由度的相似变换;如果只剩一个点,则仅执行 2 自由度的平移跟踪。
b. Synthetic Visual Genome 2: Extracting Large-scale Spatio-Temporal Scene Graphs from Videos https://arxiv.org/pdf/2602.23543
机构:Allen Institute for AI(华盛顿大学),丰田,微软
TLDR: SVG2(Synthetic Visual Genome 2),这是一个用于训练和评估大规模视频场景图生成任务的合成数据集。该研究通过一种全自动流水线处理了超过63.6万段视频,提取出数百万个物体实例、属性以及复杂的时空关系。为了利用这些数据,作者开发了名为 TraSeR 的视觉语言模型,该模型通过双重重采样模块(物体轨迹和时间窗口)来捕捉视频中的全局背景与局部动态。实验证明,TraSeR 在物体识别和关系预测方面显著优于 GPT-5 等现有模型,展现了结构化表示对视频问答任务的增强作用。此外,文中还探讨了数字孪生在基础模型中的必要性,并提供了详细的消融实验以验证系统设计的有效性。
方法:
- Data and Data pipeline
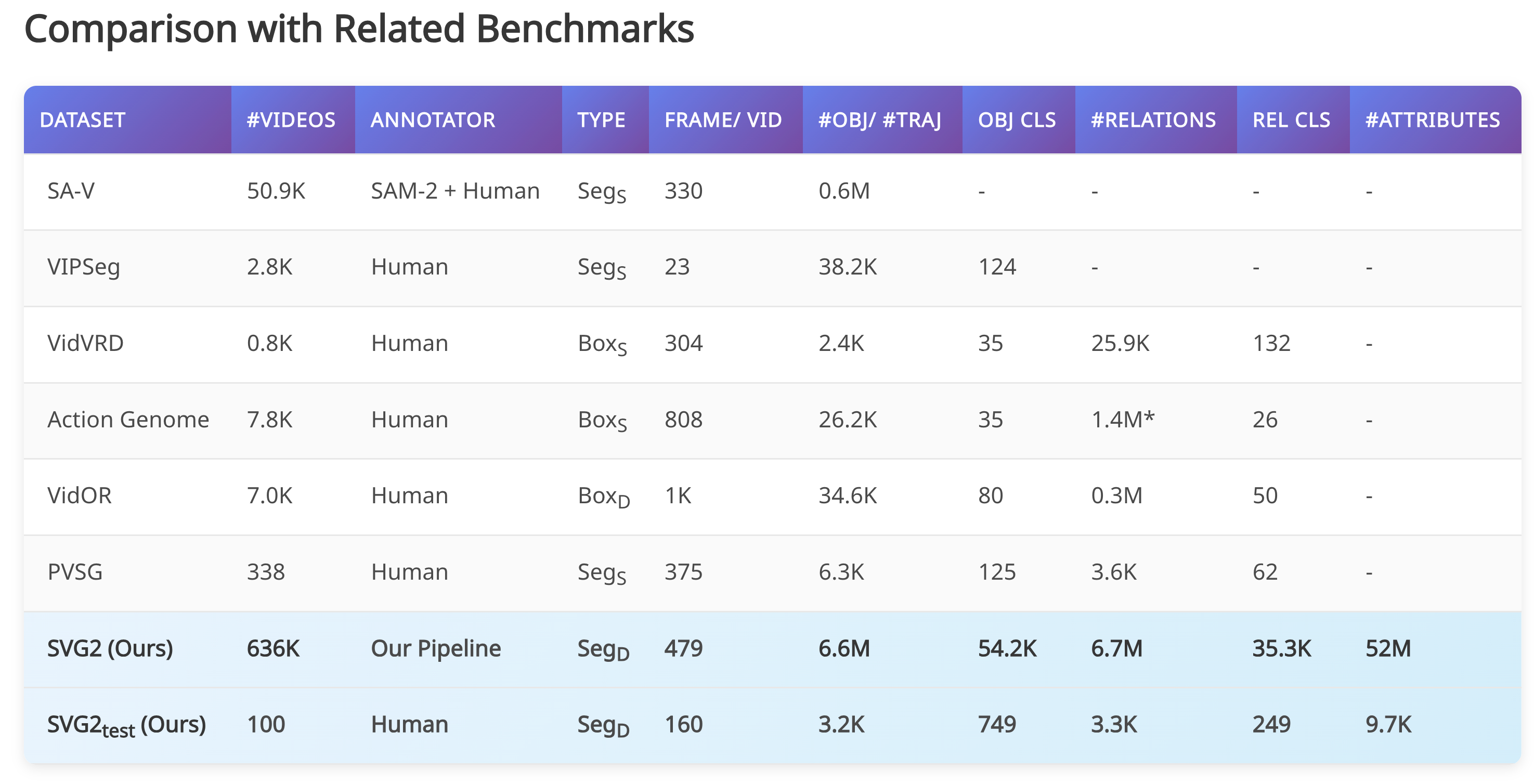
从 SA-V 中采样了43K 个视频,从 PVD 中采样了593K 个视频,得到了660 万个对象实例、5200 万个属性和670 万个时空关系
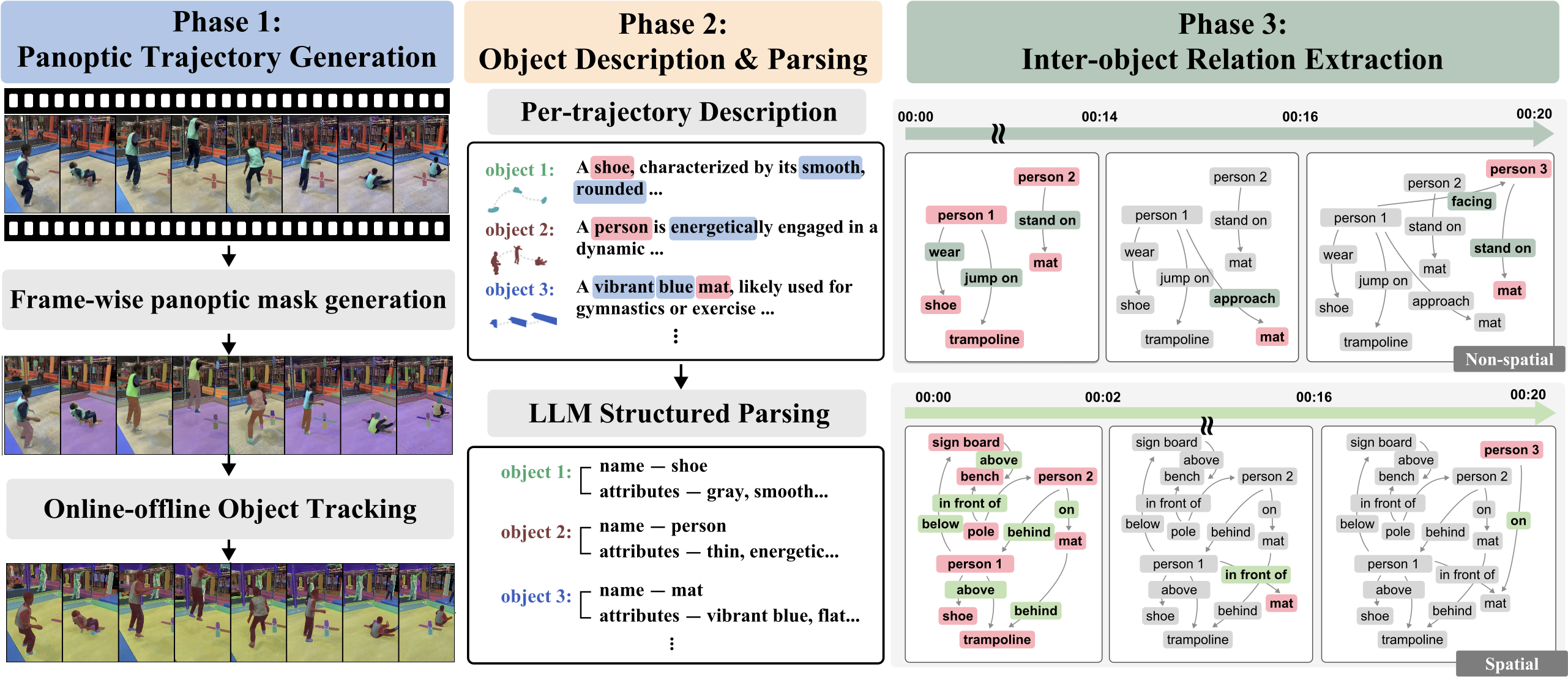
全自动化的流程集成了 SAM2、DAM (describe anything) 和 GPT-5,以生成密集的、具有时间相关性的 video scene graphs :
- 第一阶段:全景轨迹生成
- 两阶段在线-离线跟踪框架利用 SAM2 和多尺度网格提示实现动态目标发现和全局时间一致性。
- 第二阶段:对象描述与解析
- DAM-3B-Video 为每个轨道生成详细描述,然后 GPT-4-nano 提取对象名称和属性。基于 SAM3 的验证机制过滤掉不可靠的标签。
- 第三阶段:时空关系抽取
- GPT-5 推断对象间的关系,包括空间、功能、状态、运动、社交、注意力和事件级交互。
对 100 个抽样视频进行人工验证,结果显示对象标签的准确率为93.8% ,属性的准确率为88.3%,关系的准确率为 85.4% 。
- TRASER Model
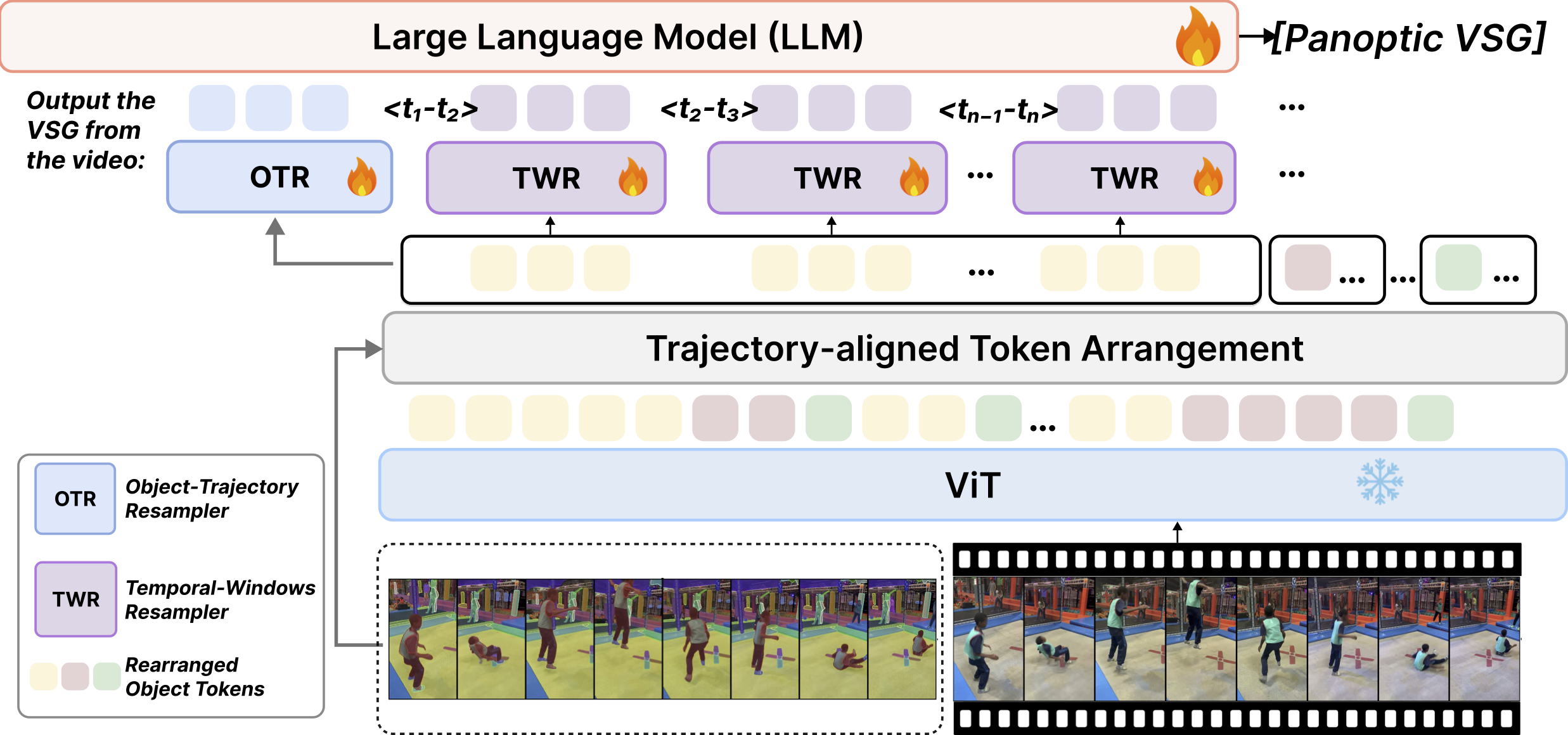
TRASER VLM,通过一次前向传播,从原始视频和全景物体轨迹生成 structured video scene graphs (VSG)
- Trajectory-Aligned Token Arrangement: Binds ViT tokens to object trajectories based on segmentation coverage, producing identity-preserving token streams with explicit trajectory boundaries.
- Object-Trajectory Resampler: Aggregates global semantics over each object's entire temporal span using Perceiver-Resampler with learnable latent queries.
- Temporal-Window Resampler: Partitions video into temporal windows and resamples each window independently, preserving fine-grained motion and temporal dynamics crucial for relation detection.
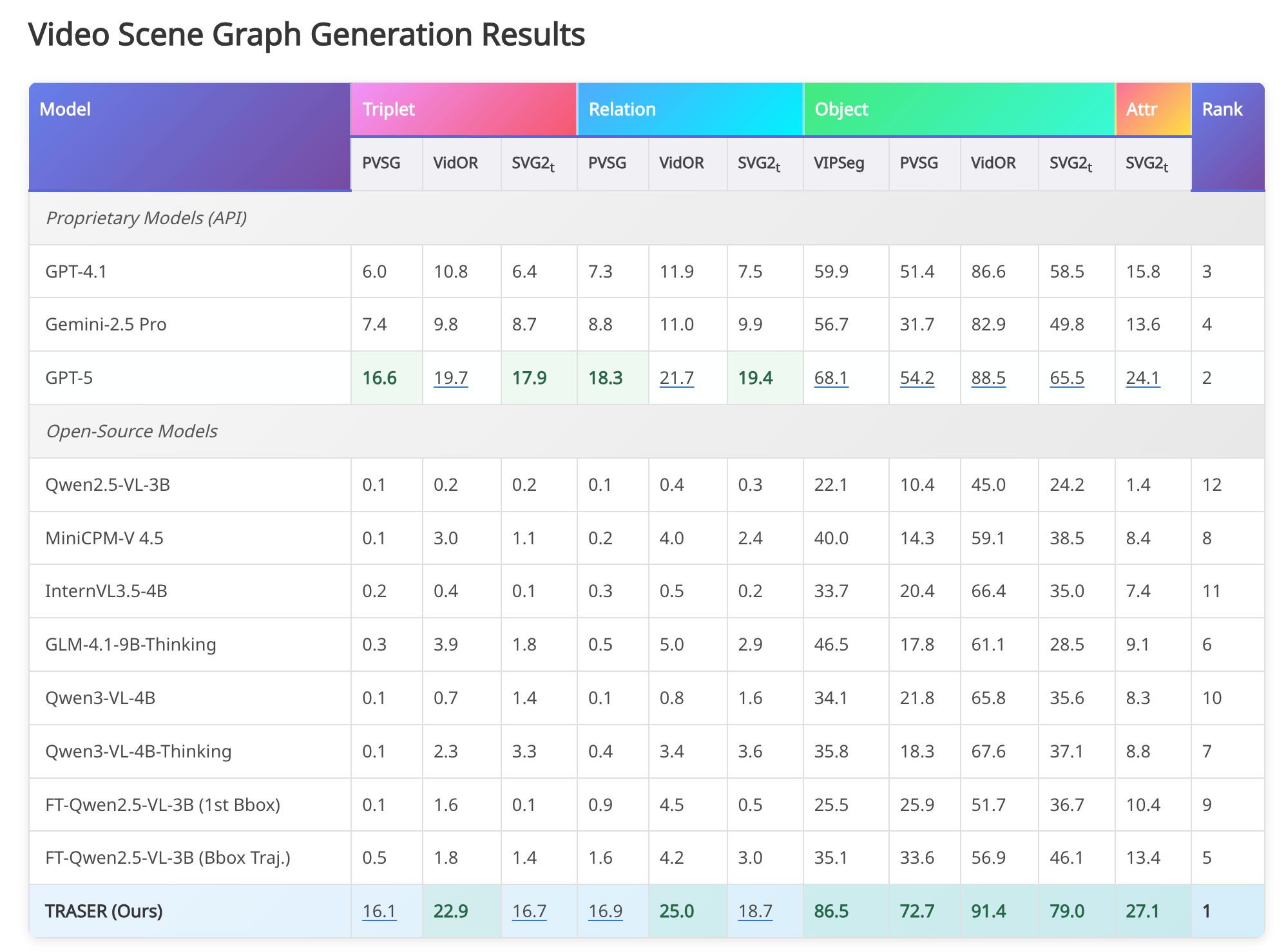
结果
从 https://huggingface.co/UWGZQ/TRASER 来看,应该是基于 Qwen2.5VL 3B 的一个模型,所以对比的模型基本都是类似大小的模型:
相关补充:
Video Scene Graph(VSG)一般指 视频场景图,也常见于任务 Video Scene Graph Generation (VSGG)。
把一段视频表示成一个动态关系图:
- 节点(Nodes):视频中的对象
- person
- car
- dog
- 边(Edges):对象之间的关系
- person ride bike
- dog chase cat
- 时间维度(Temporal dimension)
- 关系会随着时间变化
例如:
| 时间 | 关系 |
|---|---|
| t1 | person – holding → cup |
| t2 | person – drinking → cup |
Panoptic Video Scene Graph(PVSG)是 VSG 的一个 更强、更完整的版本。
它在 VSG 的基础上加入:Panoptic-level segmentation
即:不仅检测对象,还要给出 像素级 mask。
| 信息 | VSG | PVSG |
|---|---|---|
| object | ✅ | ✅ |
| relation | ✅ | ✅ |
| time | ✅ | ✅ |
| bounding box | ✅ | ❌(通常不用) |
| segmentation mask | ❌ | ✅ |
c. CoPE-VideoLM https://sayands.github.io/cope/
机构:微软,斯坦福,ETH
TLDR:CoPE-VideoLM 是一种创新的视频语言模型架构,旨在通过利用视频编解码器原语(video codec primitives)(如运动矢量和残差)来提升处理效率。传统模型通常将视频视为冗余的 RGB 图像序列,而 CoPE-VideoLM 仅对关键的 I 帧进行深度视觉编码,并对 P 帧采用轻量级的 Δ-Encoder。这种设计充分利用了视频压缩标准中的稀疏性,大幅减少了计算开销。实验表明,该方法在保持甚至超越主流模型性能的同时,最高可缩减 93% 的 Token 使用量。此外,它将生成首个 Token 的时间(TTFT)缩短了 86%,为实时机器人交互和超长视频理解提供了高效的解决方案。该研究展示了将底层图像压缩技术与高层语义推理结合的巨大潜力。
动机:
当你观看一段视频时,你的大脑并不会每秒钟重新解析 30 张完整的高清图片。相反,你会下意识地关注滑板的轨迹和人物的动作。然而,目前的视频大模型却极其低效:它们要么强行压缩帧数导致丢失细节,要么试图处理每一帧的全部像素,这不仅消耗了海量的计算资源,还受限于极短的上下文窗口。
研究人员发现,我们其实一直坐在一座被忽视的金矿上——视频压缩技术(Video Compression)。在 H.264 或 HEVC 等标准格式中,视频早已被精简为“帧间变化”的集合。为什么不让 AI 直接读取这些已经压缩好的信息呢?
传统模型处理的是冗余的 RGB 像素,而 CoPE-VideoLM 提取的是编解码原语(Codec Primitives)。
- 运动矢量(Motion Vectors, τ):描述了图像块随时间的位移,类似于粗糙的光流。
- 残差(Residuals, δ):捕捉了运动补偿后剩下的微小像素修正。
通过这种方式,模型只需要偶尔看一眼完整的“关键帧”(I-frame),其余时间只需通过以下公式追踪变化:
方法:
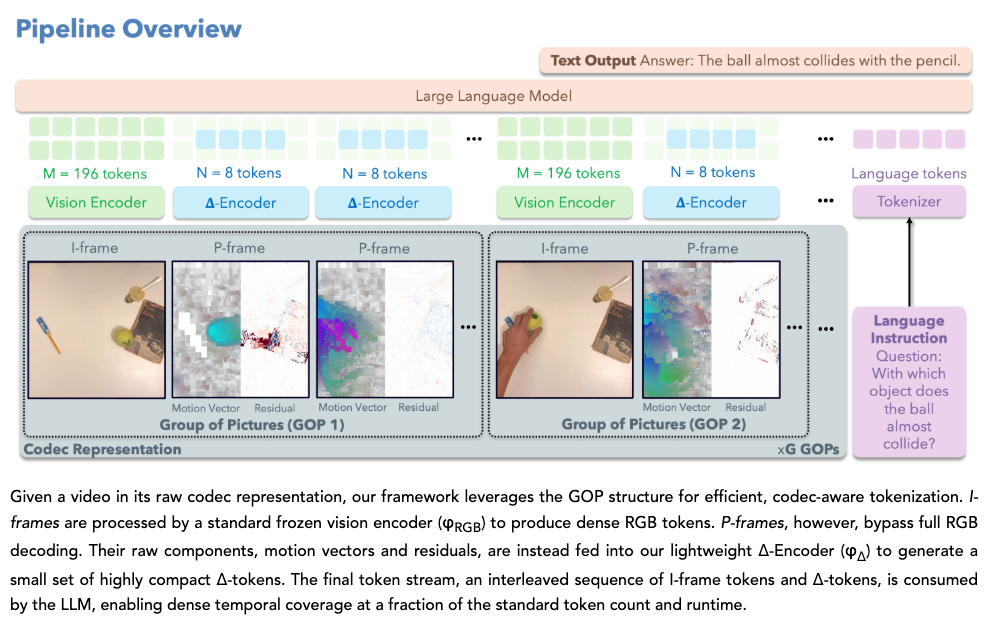
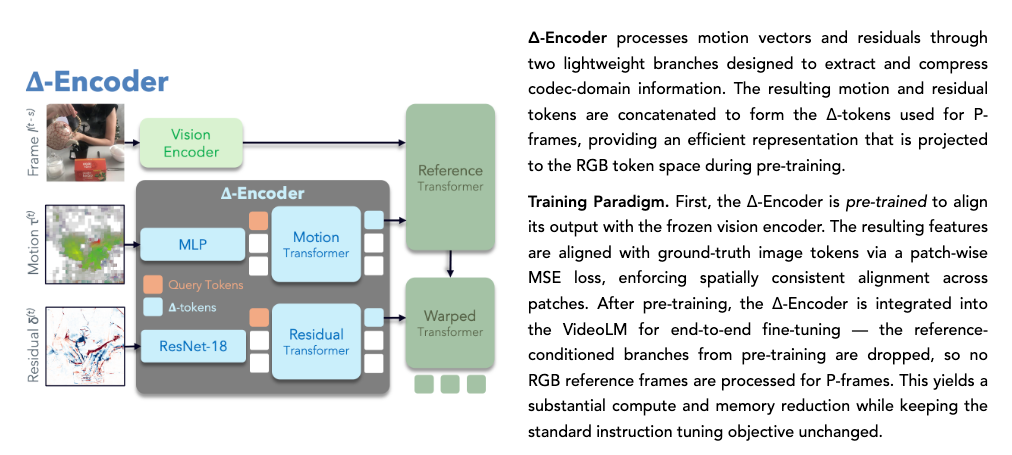
CoPE-VideoLM 的核心在于一套轻量级的 Δ-Encoder,它将复杂的像素对比转换成了简洁的 Token 序列。以下是其实现的具体步骤:
- 识别 GOP 结构
模型首先解析视频的图片组(Group of Pictures - GOP)结构。它将视频分为独立的 I 帧(完整图像)和预测性的 P 帧(仅包含变化)。I 帧通过标准的视觉编码器处理,而 P 帧则进入专有的高效通道。
- Δ-Encoder 并行处理
Δ-Encoder 包含两个专门的分支来提取 P 帧中的特征:
- 运动分支:使用MLP处理运动矢量,并通过运动 Transformer 聚合为极少量的“运动 Token”。
- 残差分支:使用轻量级的 ResNet-18 提取残差中的视觉修正,再通过残差 Transformer 压缩为“残差 Token”。 这两个分支最终生成的 Δtokens 仅包含 8 个 Token,远少于传统图像所需的 196 个 Token。
- 两阶段训练对齐
为了让语言模型能理解这些“变化 Token”,研究人员设计了精妙的训练策略:
- 预训练阶段:通过模拟视频解码过程,强迫 Δ-tokens 在嵌入空间中与真实的 RGB 图像特征对齐。其核心目标是最小化预测 Token 与真实图像 Token 之间的回归损失(LMSE)。
- 端到端微调:将预训练好的编码器接入视频大模型(如 LLaVA-Video),在海量问答数据上进行微调,让模型学会如何交替处理完整图像和这些“增量信息”。
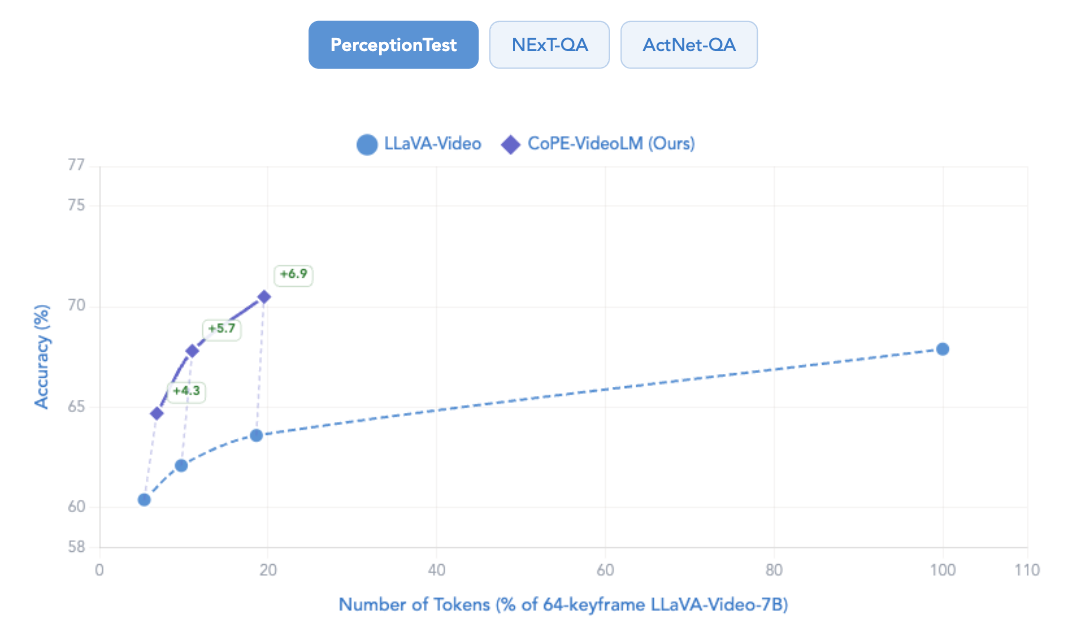
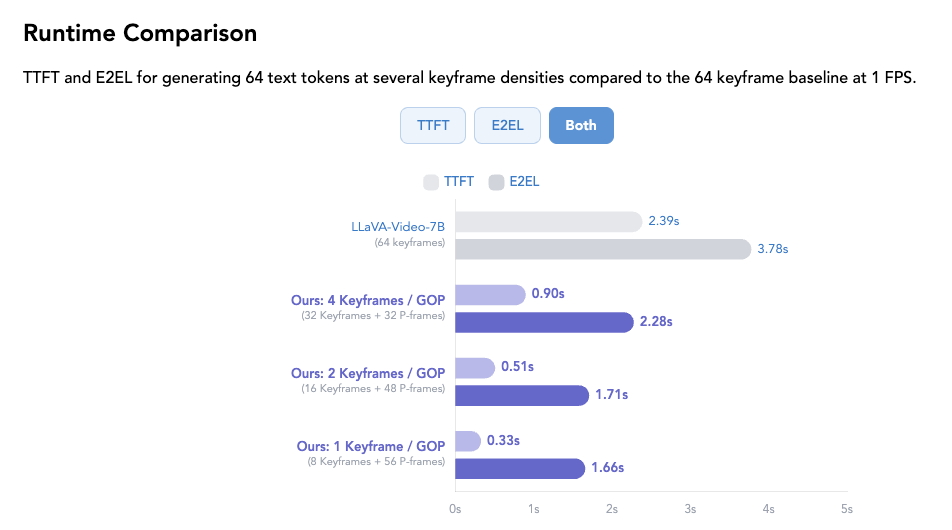
结果
与 LLaVA-Video 对比,在 token 需求量(budge)和推理速度上都是明显更优
d. Beyond Language Modeling: An Exploration of Multimodal Pretraining https://beyond-llms.github.io/
机构:Meta,NYU
TLDR:多模态预训练中 MoE 和 RAE 是两个 work 的东西。主要做了以下实验:

github io 上比较完整(而且原文有点太长了),可以移步网页进行浏览