作者:Gautam Rajendrakumar Gare, Neehar Peri, Matvei Popov, Shruti Jain, John Galeotti, Deva Ramanan机构:Carnegie Mellon University, RoboflowarXiv:2603.23455v1日期:2026-03-24
Abstract(原文)
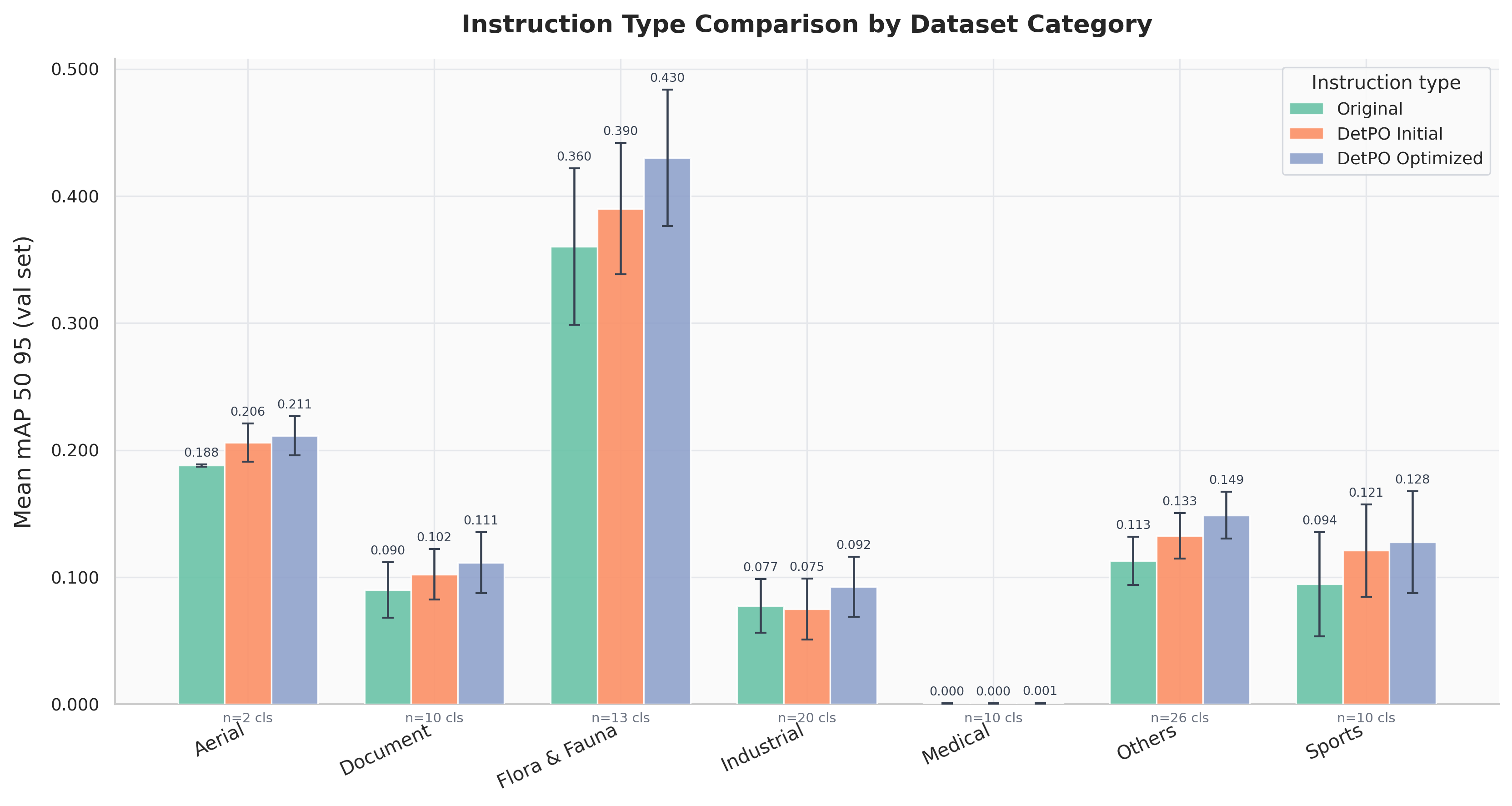
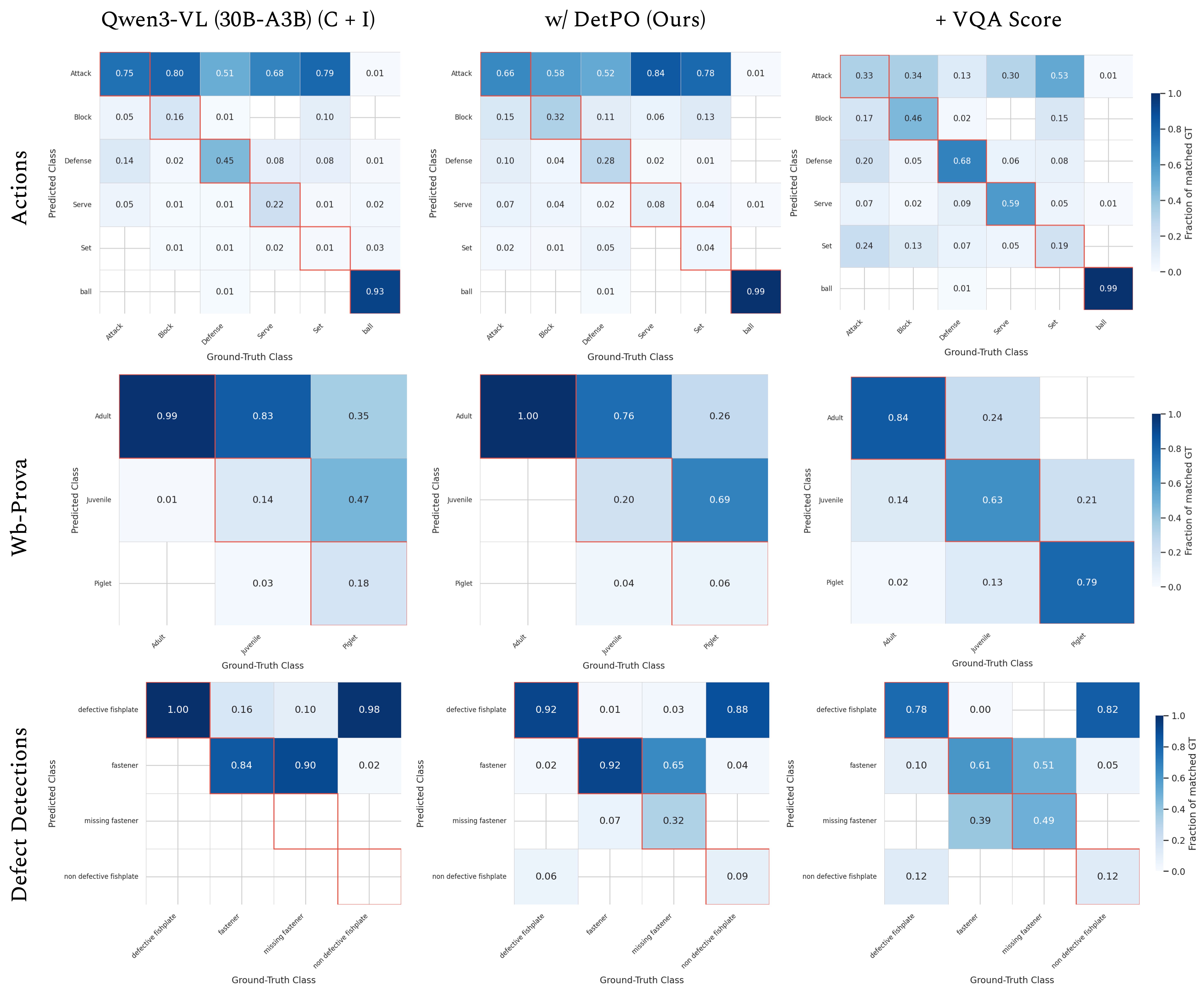
Multi-Modal LLMs (MLLMs) demonstrate strong visual grounding capabilities on popular object detection benchmarks like OdinW-13 and RefCOCO. However, state-of-the-art models still struggle to generalize to out-of-distribution classes, tasks and imaging modalities not typically found in their pre-training. While in-context prompting is a common strategy to improve performance across diverse tasks, we find that it often yields lower detection accuracy than prompting with class names alone. This suggests that current MLLMs cannot yet effectively leverage few-shot visual examples and rich textual descriptions for object detection. Since frontier MLLMs are typically only accessible via APIs, and state-of-the-art open-weights models are prohibitively expensive to fine-tune on consumer-grade hardware, we instead explore black-box prompt optimization for few-shot object detection. To this end, we propose Detection Prompt Optimization (DetPO), a gradient-free test-time optimization approach that refines text-only prompts by maximizing detection accuracy on few-shot visual training examples while calibrating prediction confidence. Our proposed approach yields consistent improvements across generalist MLLMs on Roboflow20-VL and LVIS, outperforming prior black-box approaches by up to 9.7%.
作者:Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, Randall Balestriero机构:Mila & Université de Montréal, New York University, Samsung SAIL, Brown UniversityarXiv:2603.19312v2日期:2026-03-24
Abstract(原文)
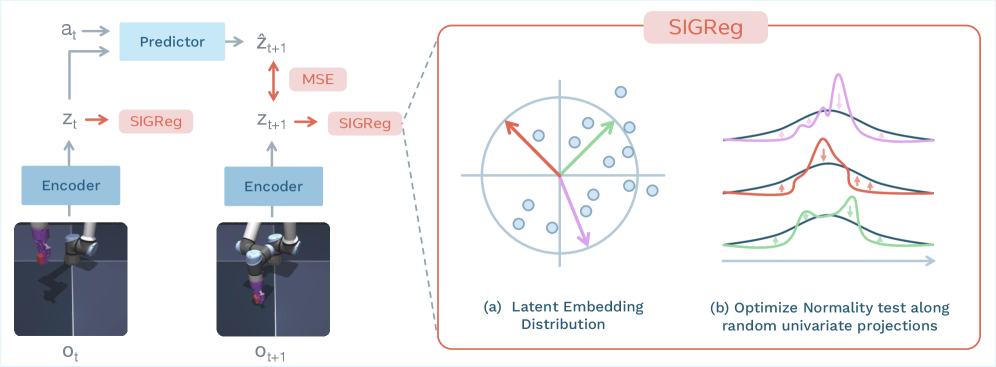
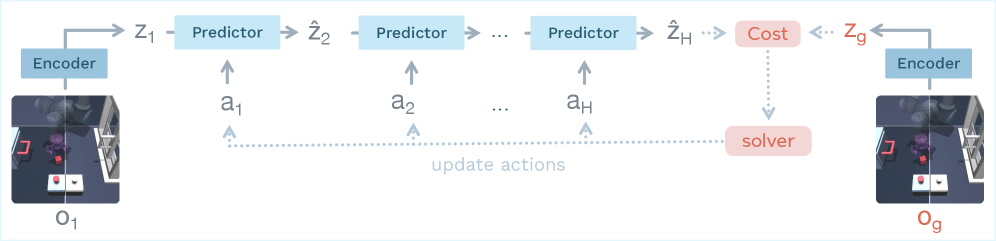
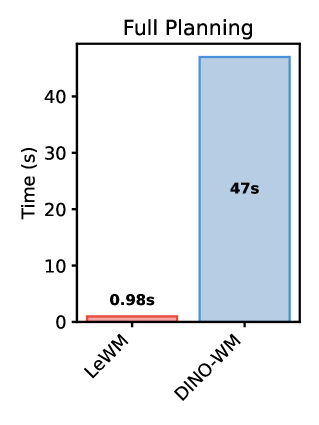
Joint Embedding Predictive Architectures (JEPAs) offer a compelling framework for learning world models in compact latent spaces, yet existing methods remain fragile, relying on complex multi-term losses, exponential moving averages, pre-trained encoders, or auxiliary supervision to avoid representation collapse. In this work, we introduce LeWorldModel (LeWM), the first JEPA that trains stably end-to-end from raw pixels using only two loss terms: a next-embedding prediction loss and a regularizer enforcing Gaussian-distributed latent embeddings. This reduces tunable loss hyperparameters from six to one compared to the only existing end-to-end alternative. With 15M parameters trainable on a single GPU in a few hours, LeWM plans up to 48× faster than foundation-model-based world models while remaining competitive across diverse 2D and 3D control tasks. Beyond control, we show that LeWM’s latent space encodes meaningful physical structure through probing of physical quantities. Surprise evaluation confirms that the model reliably detects physically implausible events.
在单卡、小模型条件下,实现了兼顾稳定性、规划速度和控制性能的 latent world model。
理论意义
重新界定了端到端 JEPA world model 训练的“最低必要条件”。
复杂多损失目标并不天然更好,目标更少、梯度更一致时,训练可能反而更稳。
实践价值
显著降低了复现端到端像素世界模型的门槛。
对需要在线规划的场景,小 latent + 小模型带来的低时延非常实用。
局限性
长时域规划仍弱,误差在自回归 rollout 中会不断累积。
依赖离线数据覆盖。
部分关键工程设计缺少隔离验证。
核心理论保证主要来自 SIGReg 本身,而非本文对 action-conditioned world model 的完整新证明。
6. 论文解读:stable-worldmodel-v1
作者:未提供机构:未提供arXiv:2602.08968v2日期:未提供
Abstract 对照
原文
World Models have emerged as a powerful paradigm for learning compact, predictive representations of environment dynamics, enabling agents to reason, plan, and generalize beyond direct experience. Despite recent interest in World Models, most available implementations remain publication-specific, severely limiting their reusability, increasing the risk of bugs, and reducing evaluation standardization. To mitigate these issues, we introduce stable-worldmodel (SWM), a modular, tested, and documented world-model research ecosystem that provides efficient data-collection tools, standardized environments, planning algorithms, and baseline implementations. In addition, each environment in SWM enables controllable factors of variation, including visual and physical properties, to support robustness and continual learning research. Finally, we demonstrate the utility of SWM by using it to study zero-shot robustness in DINO-WM.
作者:Claudia Cuttano, Gabriele Trivigno, Christoph Reich, Daniel Cremers, Carlo Masone, Stefan Roth机构:Politecnico di Torino, TU Darmstadt, TU Munich, hessian.AI, ELIZA, MCMLarXiv:2603.28480v1日期:2026-03-30
Abstract(原文)
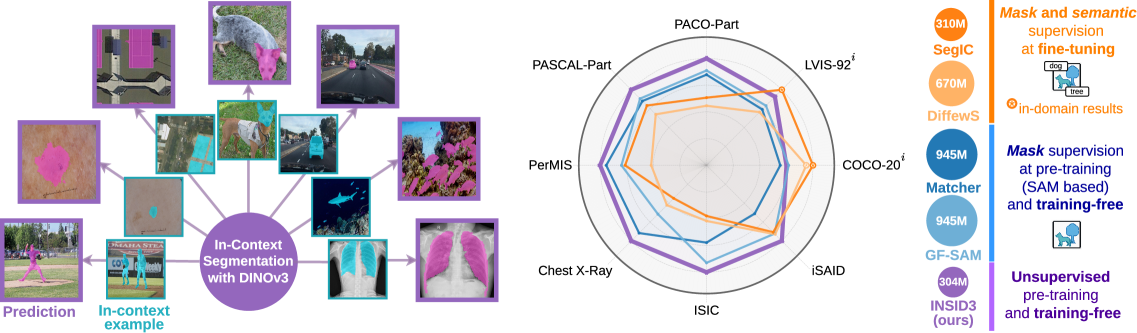
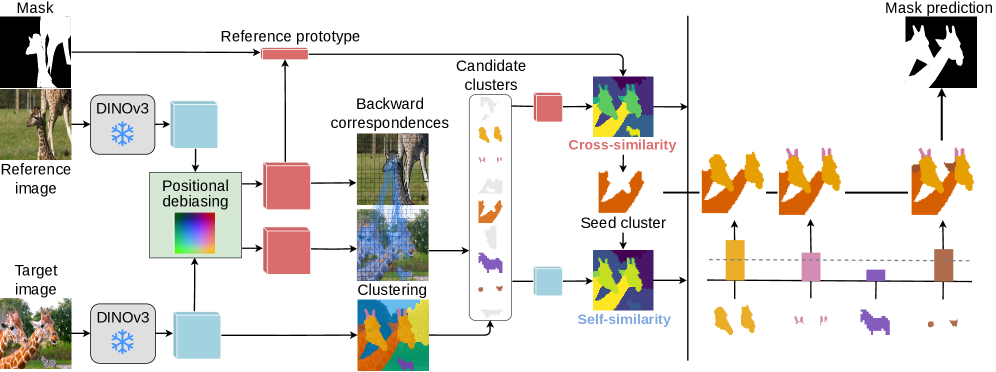
In-context segmentation (ICS) aims to segment arbitrary concepts, e.g., objects, parts, or personalized instances, given one annotated visual examples. Existing work relies on (i) fine-tuning vision foundation models (VFMs), which improves in-domain results but harms generalization, or (ii) combines multiple frozen VFMs, which preserves generalization but yields architectural complexity and fixed segmentation granularities. We revisit ICS from a minimalist perspective and ask: Can a single self-supervised backbone support both semantic matching and segmentation, without any supervision or auxiliary models? We show that scaled-up dense self-supervised features from DINOv3 exhibit strong spatial structure and semantic correspondence. We introduce INSID3, a training-free approach that segments concepts at varying granularities only from frozen DINOv3 features, given an in-context example. INSID3 achieves state-of-the-art results across one-shot semantic, part, and personalized segmentation, outperforming previous work by +7.5% mIoU, while using 3x fewer parameters and without any mask or category-level supervision.
ICS 的难点不只是“分出一个物体”,而是要根据参考图里的提示,在目标图里分出同一个概念,而且这个概念可能是类别、部件,甚至是某个特定实例。已有方法通常要么依赖微调,要么依赖 DINO + SAM 这类多模型拼接。前者容易过拟合训练分布,后者虽然泛化较好,但系统复杂,且 mask 粒度受 SAM 先验限制。
内容来源:arXiv HTML 全文(2603.28480v1),页面中的三张插图均来自原论文 HTML 版本。
8. 论文解读:Boxer
作者:Daniel DeTone, Tianwei Shen, Fan Zhang, Lingni Ma, Julian Straub, Richard Newcombe, Jakob Engel机构:Meta Reality Labs ResearcharXiv:2604.05212v1日期:2026-04-06
Abstract(原文)
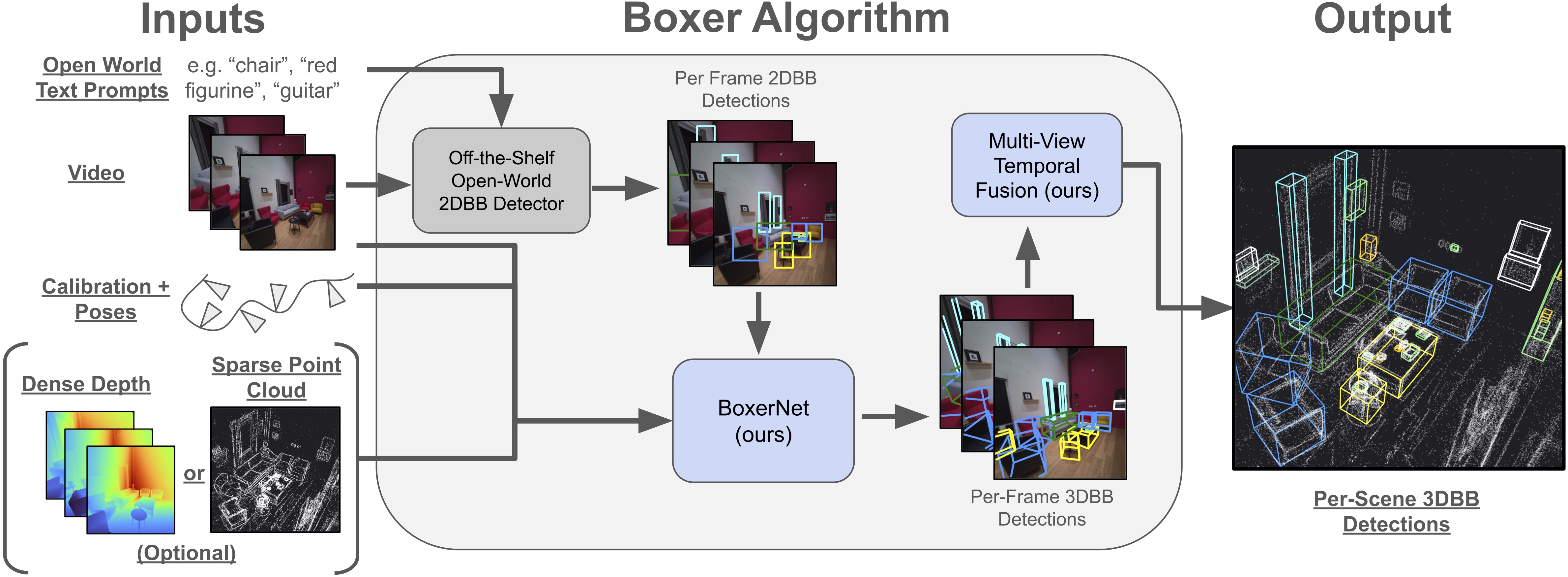
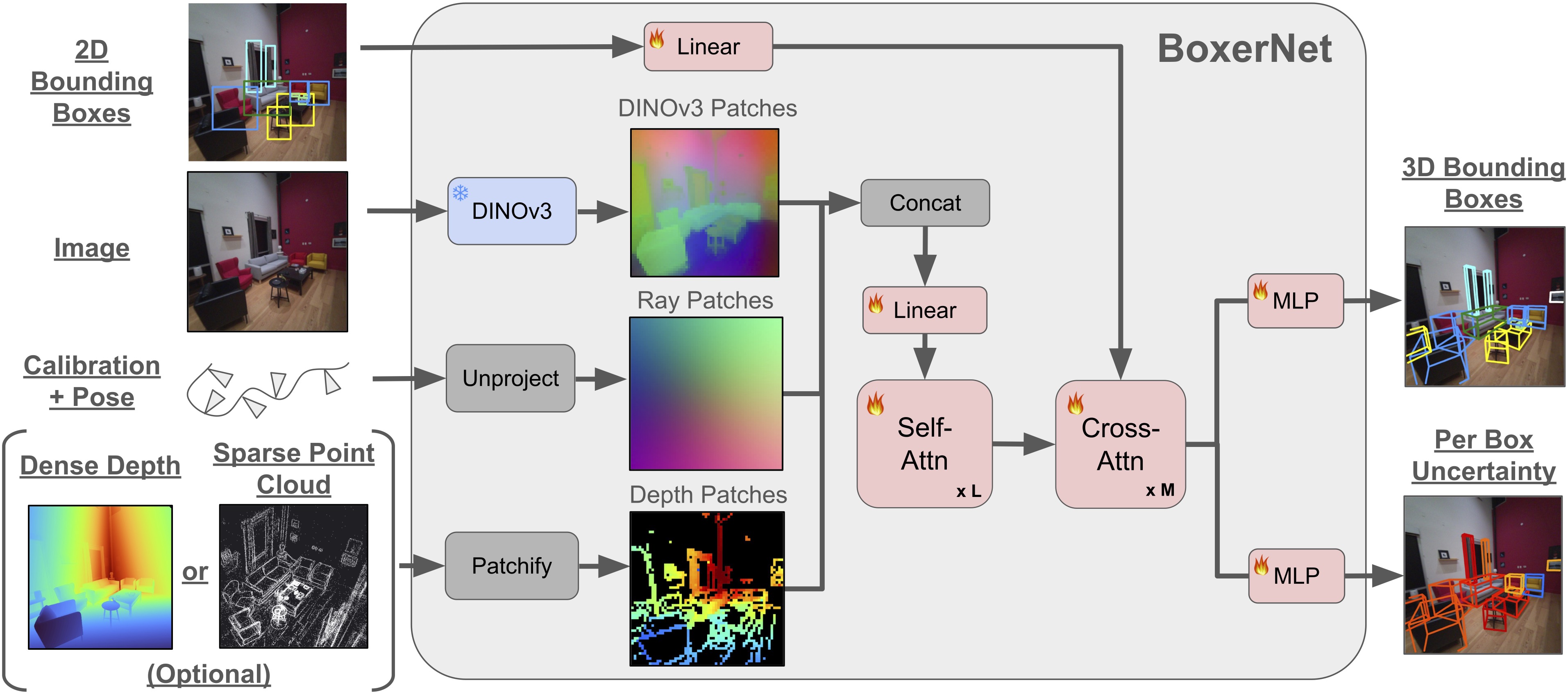
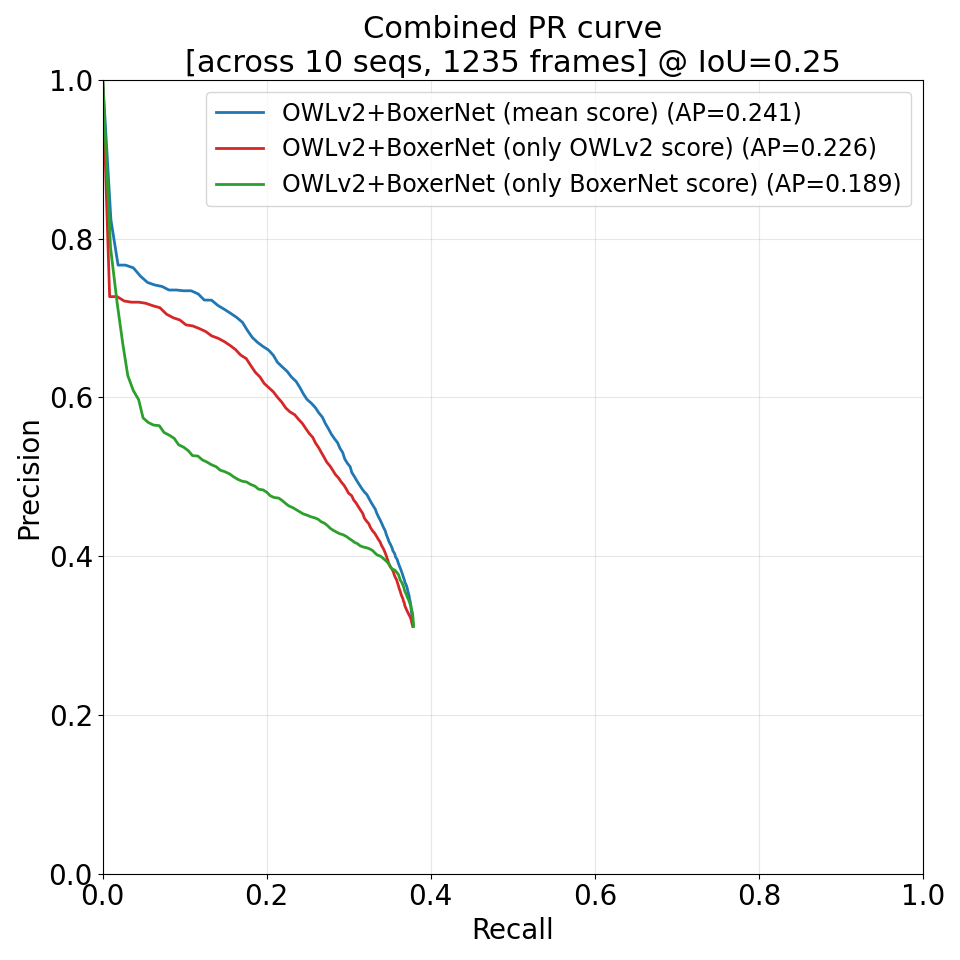
Detecting and localizing objects in space is a fundamental computer vision problem. While much progress has been made to solve 2D object detection, 3D object localization is much less explored and far from solved, especially for open-world categories. To address this research challenge, we propose Boxer, an algorithm to estimate static 3D bounding boxes (3DBBs) from 2D open-vocabulary object detections, posed images and optional depth either represented as a sparse point cloud or dense depth. At its core is BoxerNet, a transformer-based network which lifts 2D bounding box (2DBB) proposals into 3D, followed by multi-view fusion and geometric filtering to produce globally consistent de-duplicated 3DBBs in metric world space. Boxer leverages the power of existing 2DBB detection algorithms (e.g., DETIC, OWLv2, SAM3) to localize objects in 2D. This allows the main BoxerNet model to focus on lifting to 3D rather than detecting, ultimately reducing the demand for costly annotated 3DBB training data. Extending the CuTR formulation, we incorporate an aleatoric uncertainty for robust regression, a median depth patch encoding to support sparse depth inputs, and large-scale training with over 1.2 million unique 3DBBs. BoxerNet outperforms state-of-the-art baselines in open-world 3DBB lifting, including CuTR in egocentric settings without dense depth (0.532 vs. 0.010 mAP) and on CA-1M with dense depth available (0.412 vs. 0.250 mAP). Project page with code available here: https://facebookresearch.github.io/boxer.
Abstract(中文翻译)
在空间中检测并定位物体是计算机视觉中的基础问题。虽然 2D 目标检测已经取得了很大进展,但 3D 目标定位仍远未解决,尤其是在开放世界类别上。为解决这一问题,作者提出 Boxer:它从 2D 开放词汇检测结果、带位姿图像以及可选深度输入中估计静态 3D 边界框,深度既可以是稀疏点云,也可以是稠密深度。其核心模块 BoxerNet 是一个基于 Transformer 的网络,用来把 2D 边界框 proposal 提升到 3D;之后再通过多视角融合和几何过滤,得到全局一致、去重后的米制 3D 边界框。Boxer 直接利用已有 2D 检测器(如 DETIC、OWLv2、SAM3)完成 2D 定位,因此 BoxerNet 可以把容量集中在 2D 到 3D 的 lifting,而不是重复学习检测,从而减少对昂贵 3D 标注数据的依赖。在 CuTR 的基础上,作者加入了 aleatoric uncertainty[sidbar:Aleatoric Uncertainty|指观测噪声本身带来的不确定性,例如遮挡、模糊或深度缺失。模型显式预测这类不确定性,可以在训练时降低高噪声样本对回归目标的破坏。本文用它给 3D 框回归配一个可学习的置信估计,并进一步参与最终排序。]、中值深度 patch 编码,以及超过 120 万个唯一 3D 边界框的大规模训练。实验表明,BoxerNet 在开放世界 3D 框 lifting 任务上超过现有最强基线:例如在第一人称、无稠密深度的场景中,相比 CuTR 达到 0.532 vs. 0.010 mAP;在有稠密深度的 CA-1M 上达到 0.412 vs. 0.250 mAP。
TLDR
这篇论文的核心做法不是重新做一个端到端 3D 检测器,而是把问题拆成“先用开放词汇 2D 检测找到东西,再把 2D 框提升成 3D 框”。这让 Boxer 直接继承互联网规模 2D 检测器的语义覆盖,同时把学习重点放在几何 lifting 上。
提出了一个实用的开放世界 3D 框 pipeline:开放词汇 2D 检测 + 2D 到 3D lifting + 多视角融合。
提出 BoxerNet,用统一的图像、ray、深度 patch 表示兼容稀疏和稠密几何输入。
在多个数据集上系统证明,这条路线比 CuTR 等现有 lifting 基线更稳、更强。
理论意义
它说明开放世界 3D 检测未必需要端到端统一建模,合理分解任务同样可以拿到更好的效果。
它也说明 3D 感知里“输入接口设计”本身是重要研究点,尤其是在多设备、多传感器环境下。
实践价值
对 AR、机器人和数字孪生来说,这种模块化方案更容易接入现有 2D 基础模型。
如果你手头已经有强 2D 检测器和带位姿视频,BoxerNet 这类 lifting 模块比重新训一个 3D 检测器更现实。
局限性
训练严重依赖大规模多源数据,且包含内部数据;普通研究者复现到同等性能并不容易。
多视角融合仍以启发式规则为主,不是可学习的统一优化目标。
论文主要评估 class-agnostic mAP,对开放词汇语义质量本身分析不足。
主文与补充材料在参数量表述上存在口径差异,工程细节还需要看代码确认。
一句话评价:这篇论文最重要的价值,不是提出了一个完全新的 3D 表示,而是把“开放世界语义”与“米制 3D 几何”用一个很实用的接口接了起来,而且实验数字足够扎实,说明这条分解路线是成立的。
内容来源:本解读基于 arXiv HTML 正文整理,包含主文与补充材料的关键信息。
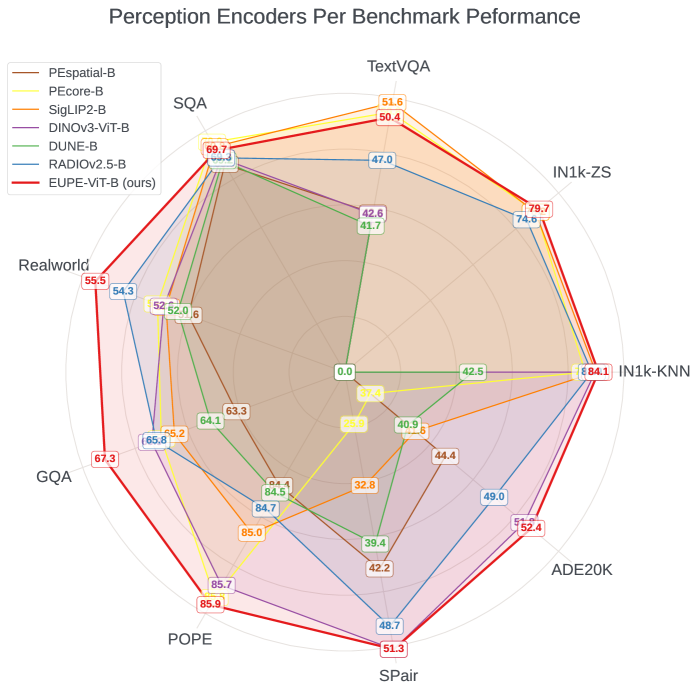
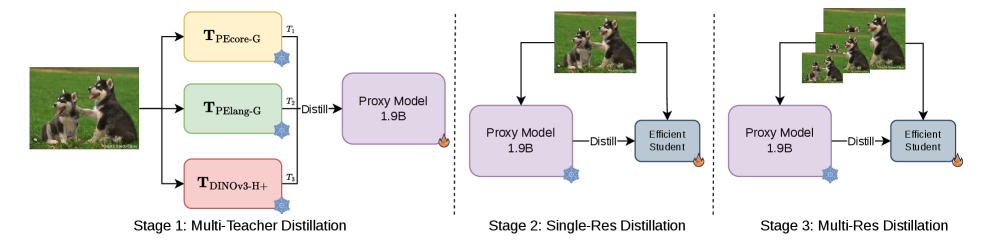
9. 论文解读:SigLino
作者:Sofian Chaybouti, Sanath Narayan, Yasser Dahou, Phúc H. Lê Khac, Ankit Singh, Ngoc Dung Huynh, Wamiq Reyaz Para, Hilde Kuehne, Hakim Hacid机构:Technology Innovation Institute; Tuebingen AI Center / University of Tuebingen; MIT-IBM Watson AI LabarXiv:2512.20157v2日期:2026-04-07
Abstract(原文)
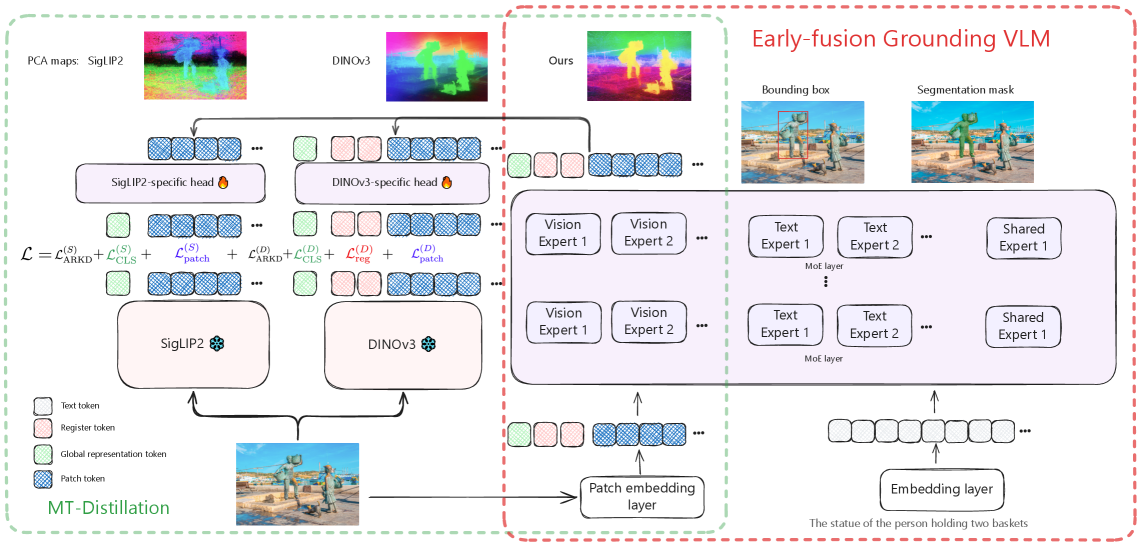
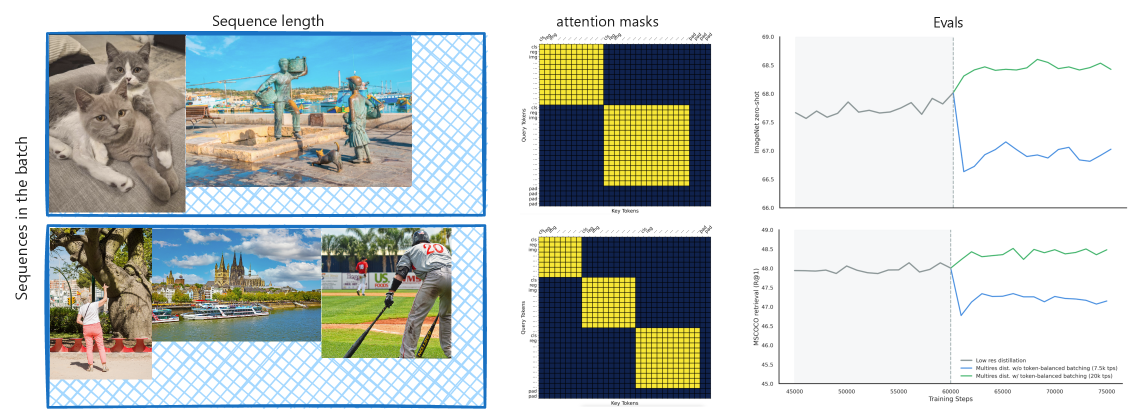
Vision foundation models trained via multi-teacher distillation offer a promising path toward unified visual representations, yet the learning dynamics and data efficiency of such approaches remain underexplored. In this paper, we systematically study multi-teacher distillation for vision foundation models and identify key factors that enable training at lower computational cost. We introduce SigLino, an efficient family of agglomerative vision foundation models that distill knowledge from SigLIP2 and DINOv3 simultaneously into Dense and Mixture-of-Experts students. We show that (1) our Asymmetric Relation-Knowledge Distillation loss preserves the geometric properties of each teacher while enabling effective knowledge transfer, (2) token-balanced batching that packs varying-resolution images into sequences with uniform token budgets stabilizes representation learning across resolutions without sacrificing performance, (3) hierarchical clustering and sampling of training data, typically reserved for self-supervised learning, substantially improves sample efficiency over random sampling for multi-teacher distillation, and (4) the resulting representations transfer effectively to early-fusion Grounding-VLMs, outperforming models trained from scratch. By combining these findings, we curate OpenLVD200M, a 200M-image corpus that demonstrates superior efficiency for multi-teacher distillation. Instantiated in a Mixture-of-Experts, our SigLino-MoE initializes an early-fusion Grounding-VLM that replaces the conventional ViT->LLM stack, demonstrating improved performance compared to a model trained from scratch. We release OpenLVD200M and five distilled checkpoints comprising MoE and dense variants.
10. 论文解读:WildDet3D: Scaling Promptable 3D Detection in the Wild
作者:Weikai Huang, Jieyu Zhang, Sijun Li, Taoyang Jia, Jiafei Duan, Yunqian Cheng, Jaemin Cho, Matthew Wallingford, Rustin Soraki, Chris Dongjoo Kim, Donovan Clay, Taira Anderson, Winson Han, Ali Farhadi, Bharath Hariharan, Zhongzheng Ren, Ranjay Krishna机构:Allen Institute for AI; University of Washington; Cornell University; UNC-Chapel Hill; Johns Hopkins UniversityarXiv:2604.08626日期:2026-04-09
Abstract(原文)
Understanding objects in 3D from a single image is a cornerstone of spatial intelligence. A key step toward this goal is monocular 3D object detection—recovering the extent, location, and orientation of objects from an input RGB image. To be practical in the open world, such a detector must generalize beyond closed-set categories, support diverse prompt modalities, and leverage geometric cues when available. Progress is hampered by two bottlenecks: existing methods are designed for a single prompt type and lack a mechanism to incorporate additional geometric cues, and current 3D datasets cover only narrow categories in controlled environments, limiting open-world transfer. In this work we address both gaps. First, we introduce WildDet3D, a unified geometry-aware architecture that natively accepts text, point, and box prompts and can incorporate auxiliary depth signals at inference time. Second, we present WildDet3D-Data, the largest open 3D detection dataset to date, constructed by generating candidate 3D boxes from existing 2D annotations and retaining only human-verified ones, yielding over 1M images across 13.5K categories in diverse real-world scenes. WildDet3D establishes a new state-of-the-art across multiple benchmarks and settings. In the open-world setting, it achieves 22.6/24.8 AP3D on our newly introduced WildDet3D-Bench with text and box prompts. On Omni3D, it reaches 34.2/36.4 AP3D with text and box prompts, respectively. In zero-shot evaluation, it achieves 40.3/48.9 ODS on Argoverse 2 and ScanNet. Notably, incorporating depth cues at inference time yields substantial additional gains (+20.7 AP on average across settings).
Abstract(中文翻译)
从单张图像中理解三维物体,是空间智能的基础能力。实现这一目标的关键一步,是单目 3D 目标检测:从输入 RGB 图像中恢复物体的尺寸、位置和朝向。若要真正适用于开放世界,这类检测器必须能泛化到封闭类别集合之外,支持多种提示方式,并在可用时利用几何线索。当前进展主要受两个瓶颈限制:现有方法通常只围绕单一提示类型设计,也缺少吸收额外几何信息的机制;现有 3D 数据集则大多只覆盖受控环境中的少量类别,限制了开放世界迁移能力。本文同时补上这两块短板。第一,作者提出 WildDet3D,一个统一的、几何感知的架构,原生支持文本、点和框提示,并可在推理时接入辅助深度信号。第二,作者构建了目前最大的开放式 3D 检测数据集 WildDet3D-Data:从现有 2D 标注生成候选 3D 框,再仅保留人工验证通过的样本,最终得到覆盖 13.5K 类别、超过 100 万张图像的真实场景数据。WildDet3D 在多个基准和设定上刷新了结果:在新提出的 WildDet3D-Bench 上,文本提示和框提示分别达到 22.6/24.8 AP3D;在 Omni3D 上分别达到 34.2/36.4 AP3D;零样本评测时在 Argoverse 2 和 ScanNet 上达到 40.3/48.9 ODS。特别地,在推理时加入深度线索后,平均还能再提升 20.7 AP。
TLDR
这篇论文做了两件彼此配套的事:一是提出支持文本、点、框多提示输入,并可在推理时接入可选深度的单目 3D 检测模型 WildDet3D;二是构建了覆盖 100 万图像、13.5K 类别的 WildDet3D-Data,解决开放世界 3D 检测数据太窄的问题。
图 1 和图 3 展示了整体框架:输入是一张 RGB 图像、可选深度图、可选相机内参以及用户提示;输出是目标物体的 3D 框,包括中心、尺寸、旋转和置信度。由于未能获取 arXiv HTML 版本,这里不嵌入原图,改用文字说明。
核心思想
WildDet3D 的核心是把“开放词汇识别”和“几何估计”拆开做,再在中间融合。具体说,语义由图像编码器负责,几何由 RGBD 编码器负责,二者通过深度融合模块对齐;之后统一交给 promptable detector,把文本、点、框等不同提示编码到同一个查询空间,再由 3D detection head 输出 3D 框。