Motion - Video - 3D
- FrankenMotion
https://coral79.github.io/frankenmotion/
TL;DR:我们引入了第一个原子级、部件级运动控制框架,该框架由我们通过 LLM 构建的新的分层 Frankenstein 数据集(39h) 提供支持。
近年来,基于文本提示的人体动作生成技术取得了显著进展。然而,由于缺乏细粒度的、部位级的动作标注,现有方法主要依赖于序列级或动作级的描述,这限制了它们对单个身体部位动作的控制能力。
本文利用大型语言模型(LLM)的推理能力,构建了一个高质量的运动数据集,该数据集包含原子级、时间感知的部件级文本标注。与以往要么提供具有固定时间间隔的同步部件描述,要么仅依赖全局序列标签的数据集不同,我们的数据集以精细的时间分辨率捕捉异步且语义不同的部件运动。
基于此数据集,我们提出了一种基于扩散的、感知身体部位的运动生成框架,即FrankenMotion。在该框架中,每个身体部位都由其自身的、具有时间结构的文本提示引导。据我们所知,这是首个提供原子级、时间感知的、部位级运动标注,并拥有一个能够同时实现空间(身体部位)和时间(原子动作)控制的运动生成模型的研究。
实验表明,FrankenMotion 的性能优于所有先前针对我们的设置进行调整和重新训练的基线模型,并且我们的模型可以合成训练期间未见过的运动。

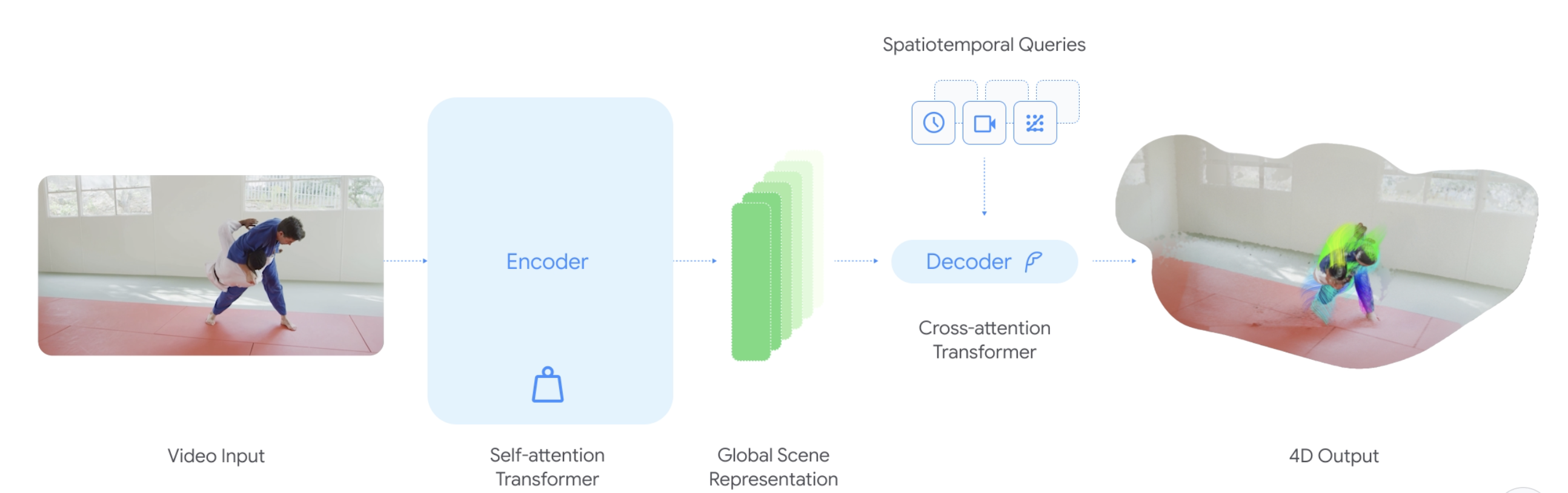
- D4RT: Teaching AI to see the world in four dimensions
https://d4rt-paper.github.io/ (没开源)
功能:快速、准确的 4D 理解
凭借这种灵活的公式,该模型现在可以解决各种各样的 4D 问题,包括:
- 点跟踪:D4RT 通过查询像素在不同时间步长中的位置,可以预测其 3D 轨迹。重要的是,即使物体在视频的其他帧中不可见,模型也能做出预测。
- 点云重建:通过冻结时间和相机视角,D4RT 可以直接生成场景的完整 3D 结构,无需额外的步骤,例如单独的相机估计或逐个视频的迭代优化。
- 相机姿态估计:通过生成和对齐来自不同视角的同一时刻的 3D 快照,D4RT 可以轻松恢复相机的轨迹。
Base CV tasks
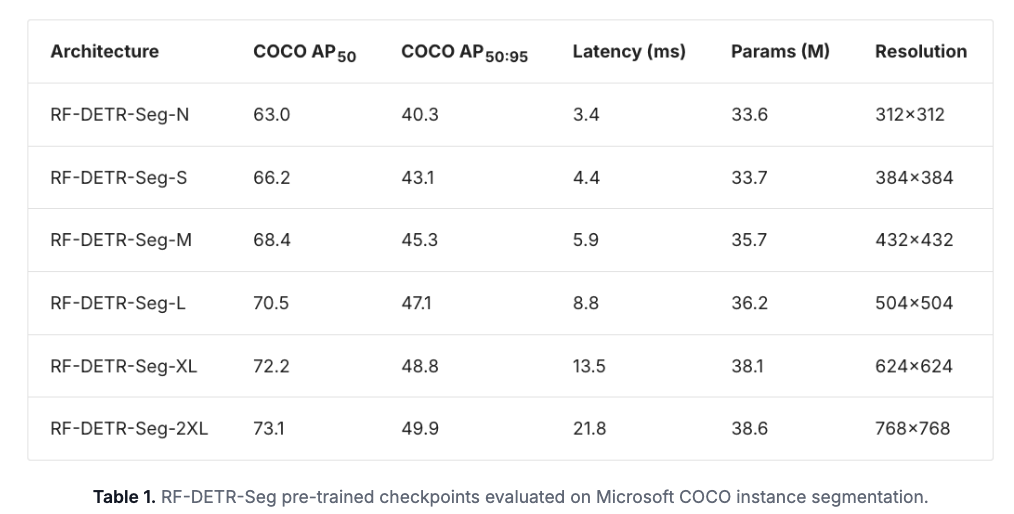
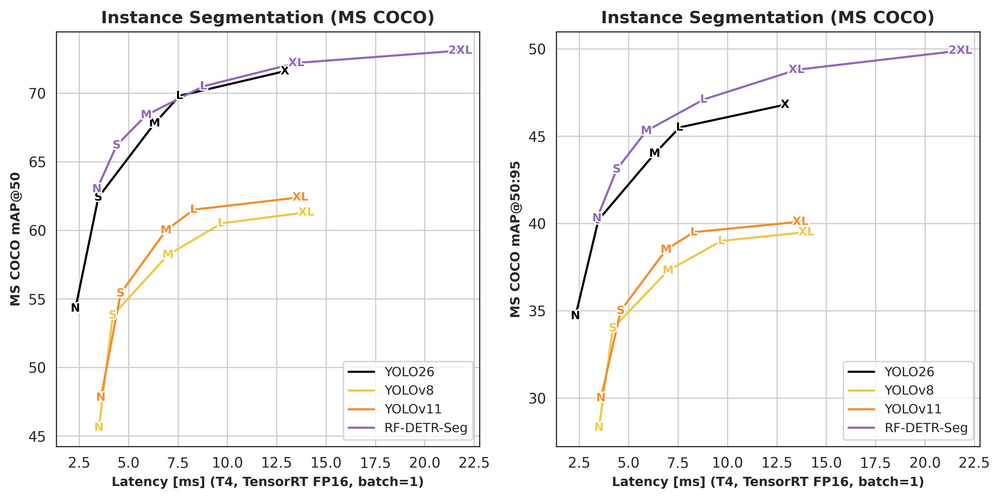
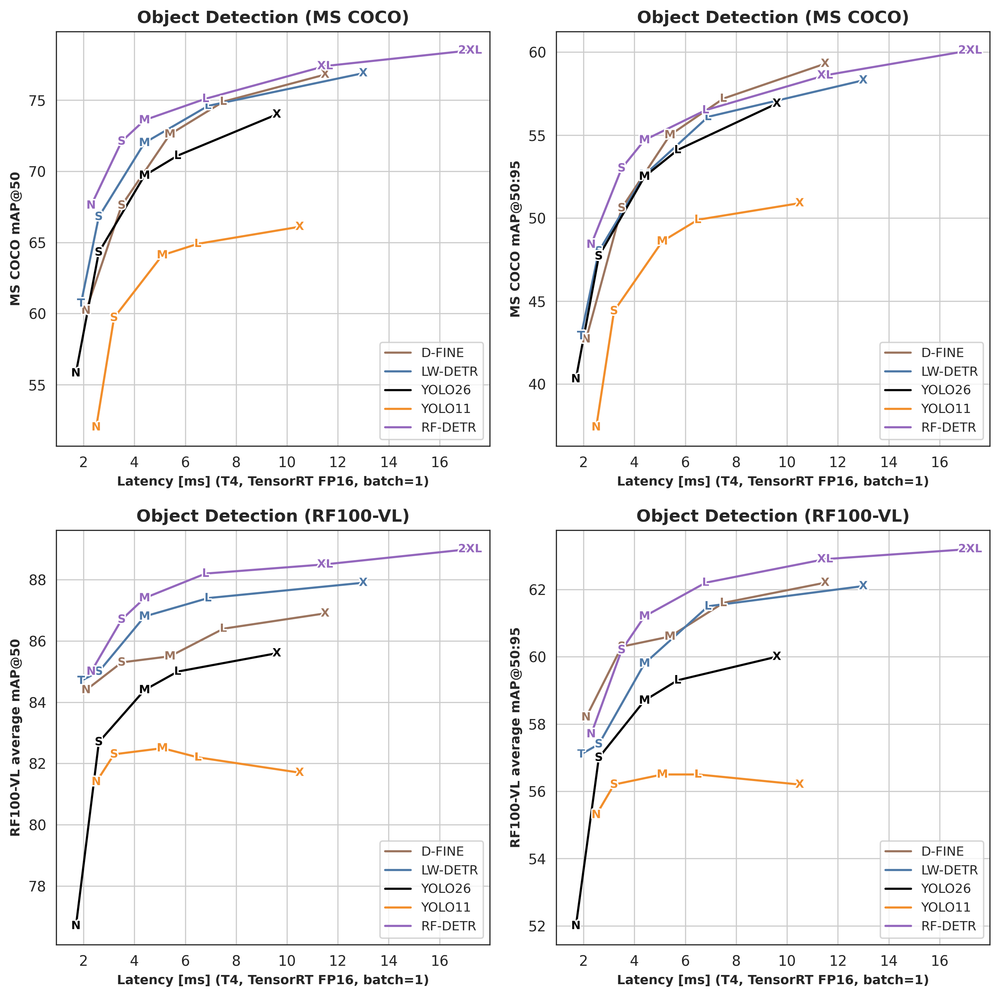
- New RF-DETR Segmentation Checkpoints from Nano to 2XLarge
- BBoxMaskPosev2
https://arxiv.org/pdf/2601.15200
除了拥挤场景外,大多数二维人体姿态估计基准测试已接近饱和。我们提出了一种自顶向下的二维姿态估计器 PMPose,它融合了概率公式和掩码条件化。PMPose 能够在不牺牲标准场景性能的前提下,提升拥挤场景下的姿态估计精度。在此基础上,我们提出了 BBoxMaskPose v2 (BMPv2),它集成了 PMPose 和一个增强的基于 SAM 的掩码细化模块。BMPv2 在 COCO 数据集上的平均精度 (AP) 比现有最佳方法提高了 1.5 个点,在 OCHuman 数据集上提高了 6 个点,成为首个在 OCHuman 数据集上 AP 超过 50 的方法。我们证明,BMP 对三维模型的二维提示能够提升拥挤场景下的三维姿态估计精度,并且二维姿态质量的提升能够直接促进三维姿态估计。在新的 OCHuman-Pose 数据集上的结果表明,多人场景下的性能更多地受到姿态预测精度的影响,而非人物检测精度的影响。

OCHuman:https://github.com/liruilong940607/OCHumanApi (occluded human bbox, seg mask and pose)
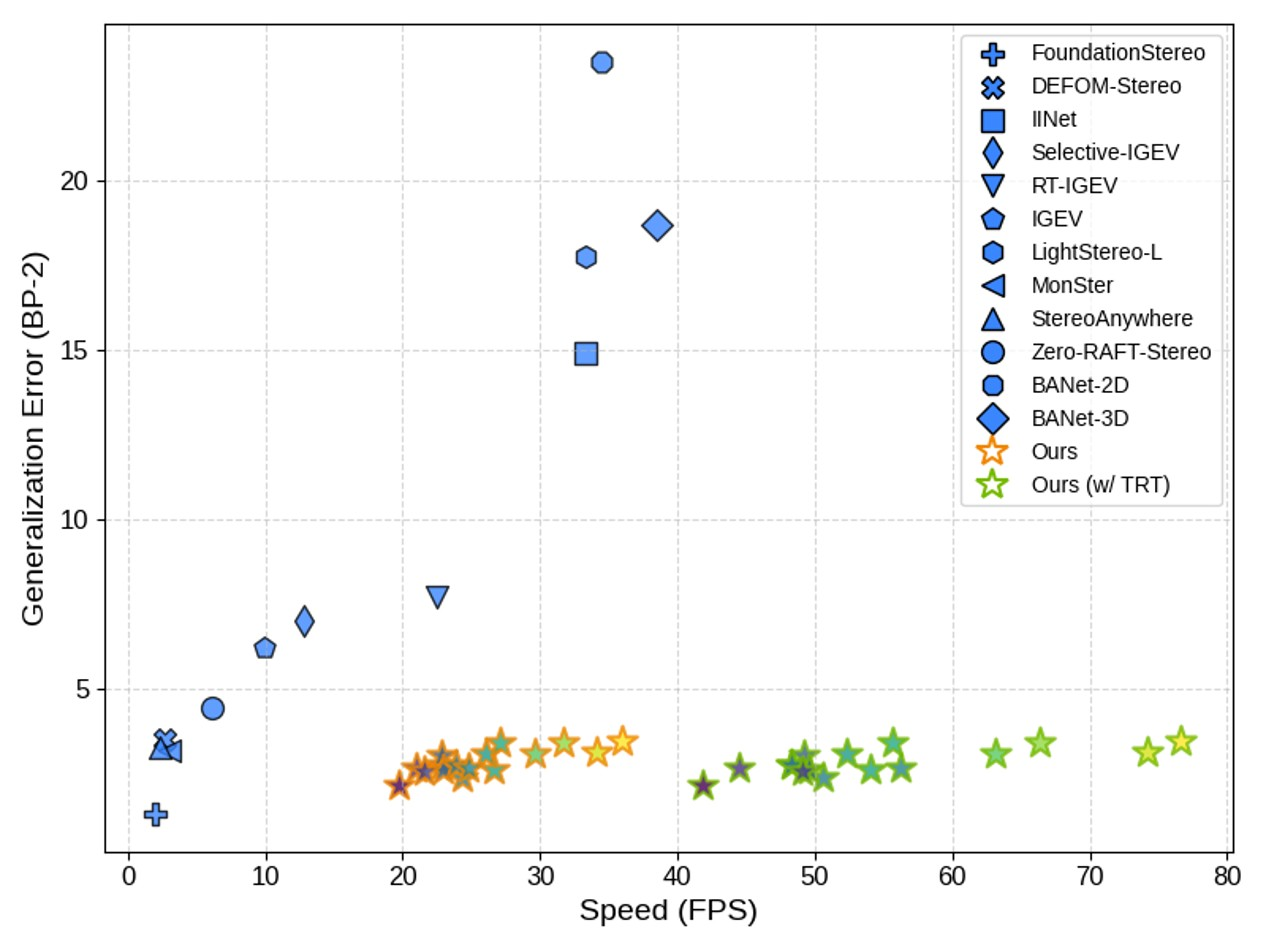
- Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching https://nvlabs.github.io/Fast-FoundationStereo/
- pervious work 《FoundationStereo: Zero-Shot Stereo Matching》 是 CVPR25 的 best paper Nomination https://arxiv.org/abs/2501.09898 2.5K stars
Stereo foundation models 虽然能够实现强大的零样本泛化能力,但其计算量仍然过大,难以应用于实时应用。另一方面,高效的立体架构为了追求速度而牺牲了鲁棒性,并且需要进行代价高昂的域微调。为了弥合这一差距,我们提出了 Fast-FoundationStereo,这是一系列架构,首次实现了在实时帧速率下强大的零样本泛化能力。我们采用了一种分而治之的加速策略,该策略包含三个组成部分:(1)知识蒸馏,将混合骨干网络压缩成一个高效的单一学生模型;(2)分块神经网络架构搜索,用于在延迟预算范围内自动发现最优的成本滤波设计,从而指数级降低搜索复杂度;(3)结构化剪枝,用于消除迭代细化模块中的冗余。此外,我们还引入了一个自动伪标签流程,用于收集 140 万个真实场景下的立体图像对,以补充合成训练数据并促进知识蒸馏。由此得到的模型运行速度比 FoundationStereo 快 10 倍以上,同时还能达到与其零样本精度非常接近的水平,从而在实时方法中树立了新的最先进水平。
- MatAnyone 2 Scaling Video Matting via a Learned Quality Evaluator
https://pq-yang.github.io/projects/MatAnyone2/ (暂时没开源)
视频抠图仍然受限于现有数据集的规模和真实性。虽然利用分割数据可以增强语义稳定性,但缺乏有效的边界监督往往会导致类似分割的抠图缺乏精细细节。为此,我们引入了一种学习型抠图质量评估器(MQE),用于评估无真实标签的Alpha抠图的语义和边界质量。它生成像素级的评估图,识别可靠区域和错误区域,从而实现细粒度的质量评估。MQE从两个方面扩展了视频抠图的规模:(1)在训练过程中作为在线抠图质量反馈,抑制错误区域,提供全面的监督;(2)作为离线数据筛选模块,结合主流视频和图像抠图模型的优势,提高标注质量。这一过程使我们能够构建一个包含2.8万个视频片段和240万帧的大规模真实世界视频抠图数据集VMReal。为了处理长视频中较大的画面变化,我们引入了一种参考帧训练策略,该策略结合了局部窗口之外的远距离帧,从而实现高效训练。我们的MatAnyone 2在合成基准测试和真实世界基准测试中均取得了最先进的性能,在所有指标上都超越了以往的方法。
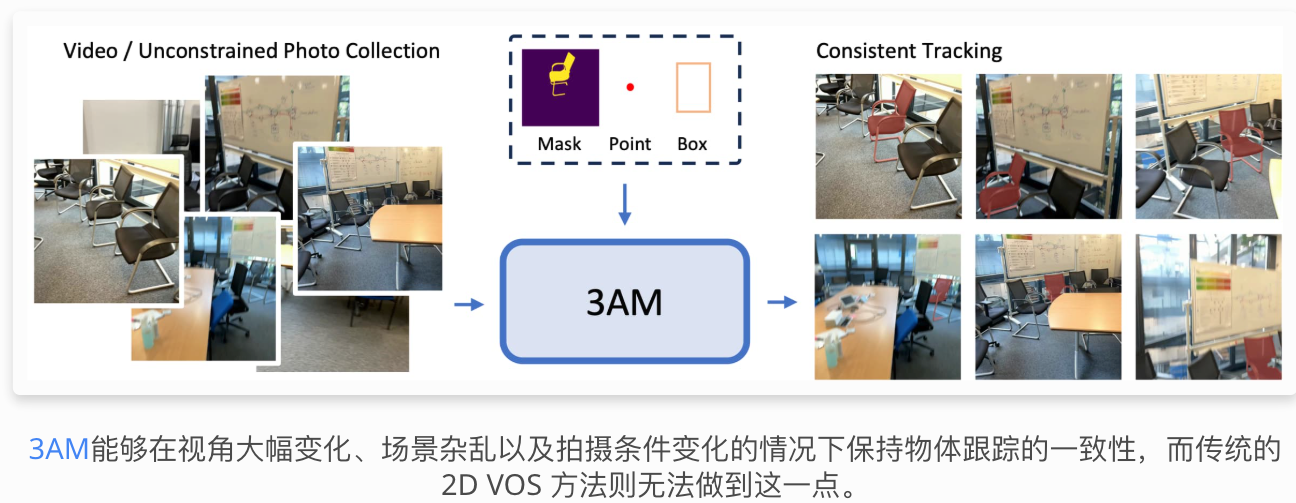
- 3AM: 3egment Anything with Geometric Consistency in Videos
https://jayisaking.github.io/3AM-Page/
诸如SAM2之类的视频对象分割方法通过基于内存的架构实现了优异的性能,但由于依赖外观特征,在视角变化较大的情况下表现不佳。传统的3D实例分割方法虽然解决了视角一致性问题,但需要相机姿态、深度图和昂贵的预处理数据。
我们提出了3AM ,这是一种训练时增强方法,它将MUSt3R中的 3D 感知特征集成到 SAM2 中。我们轻量级的特征合并器融合了编码隐式几何对应关系的多级 MUSt3R 特征。结合 SAM2 的外观特征,该模型实现了基于空间位置和视觉相似性的几何一致性识别。我们提出了一种视场感知采样策略,确保帧能够观察到空间一致的对象区域,从而实现可靠的 3D 对应关系学习。
关键在于,我们的方法在推理阶段仅需RGB输入,无需相机位姿或预处理。在具有宽基线运动的挑战性数据集(ScanNet++、Replica)上,3AM的性能显著优于SAM2及其扩展方法,在ScanNet++的选定子集上达到了90.6%的IoU,比目前最先进的VOS方法提高了15.9个百分点