1.25-1.31
首先希望各位拥抱 vibe coding: cursor,trae(字节),kiro (amazon), Opencode,Claudecode …)希望多多补充多多尝试~!
目录:
- CVPR26 NTIRE challenges:https://www.cvlai.net/ntire/2026/
- VLMs:
- PaddleOCR-VL 1.5: https://arxiv.org/abs/2601.21957
- YouTu-VL: https://arxiv.org/abs/2601.19798
- SimpleSeg-KimiVL: https://simpleseg.github.io/
- BaseCV
- C-RADIOv4: https://arxiv.org/abs/2601.17237
- Low level
- Revisiting Lightweight Low-Light Image Enhancement: From a YUV Color Space Perspective https://www.arxiv.org/abs/2601.17349
CVPR26 NTIRE challenges:https://www.cvlai.net/ntire/2026/
- NightTime Image Dehazing started!
- Reflection Removal in the Wild started!
- Image Shadow Removal started!
- Efficient Burst HDR and Restoration started!
- Low Light Image Enhancement started!
- Image Denoising started!
- Event-Based Image Deblurring started!
- Robust Deepfake Detection started!
- Photography Retouching Transfer started!
- Video Saliency Prediction started!
VLMs
PaddleOCR-VL 1.5: https://arxiv.org/abs/2601.21957
机构: 百度
内容简介: 这是一个参数规模仅为 0.9B 的超紧凑型视觉语言模型,专门用于处理复杂的真实场景文档解析任务
核心亮点:
- SOTA 性能: 在 OmniDocBench v1.5 基准测试中达到了 94.5% 的准确率。
- 鲁棒性增强: 引入了 Real5-OmniDocBench 评测集,针对扫描伪影、偏斜、弯曲、屏幕拍摄和光照等物理畸变进行了优化。在报纸类、繁体字杂志、竖排文本、PPT类、复杂公式、含公式表格、化学方程式、多栏文本、手写文字、中文公式复杂排版、日文小说等场景的OCR识别效果表现优异。
- 全能解析: 支持 irregular-shaped localization (不规则形状定位)、印章识别及多页表格合并



YouTu-VL: https://arxiv.org/abs/2601.19798
机构: 腾讯优图实验室 (Tencent Youtu Lab)
- 内容简介: 提出了一种 Vision-Language Unified Autoregressive Supervision (VLUAS) 范式,将视觉信号从“输入条件”转变为“监督目标”:现有架构在保留细粒度视觉信息方面往往存在局限性,导致多模态理解粒度较粗。我们认为这种缺陷源于现有VLM固有的次优训练范式,该范式将视觉信号仅仅视为被动的条件输入而非监督目标,从而表现出以文本为主导的优化偏差。为了缓解这一问题,我们提出了Youtu-VL,一个利用视觉语言统一自回归监督(VLUAS)范式的框架,该范式从根本上将优化目标从“视觉作为输入”转变为“视觉作为目标”。通过将视觉标记直接集成到预测流中,Youtu-VL将统一的自回归监督应用于视觉细节和语言内容。此外,我们将此范式扩展到以视觉为中心的任务,使标准的VLM无需添加特定任务即可执行以视觉为中心的任务。
- 核心亮点:
- 视觉即目标 (Vision-as-Target): 通过视觉分词器 (Vision Tokenizer) 将视觉细节集成到预测流中,保留细粒度特征。
- 架构统一: 无需任务特定组件,即可在标准 VLM 架构上完成视觉定位 (Grounding)、物体检测及像素级密集预测 (Dense Prediction)。
- 密集预测新机制: 引入 NTP-M (多标签下文预测) 损失函数,支持语义分割和深度估计任务
所以一共可以直接进行:目标检测,指代检测,GUI Agent,OCR,VQA,多模态推理,目标记数,图像分类,姿态检测,深度估计,指代分割,语义分割 12 个 task
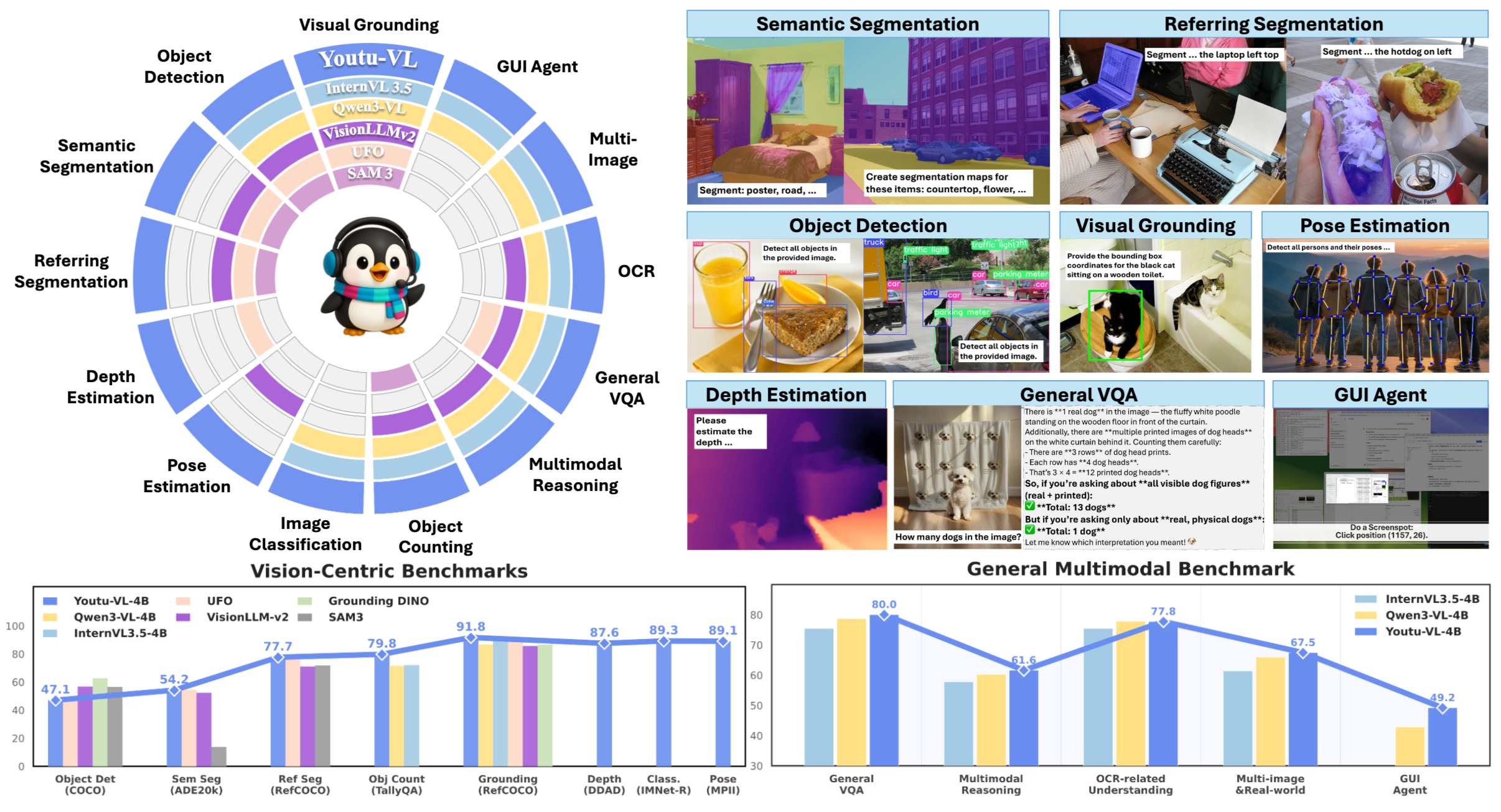
性能在一些benchmark上优于对应的Qwen3-VL模型(4B)
SimpleSeg-KimiVL: https://simpleseg.github.io/
机构: 月之暗面
- 内容简介: 该工作探索了标准 MLLM 在不依赖专门解码器 (Decoder-free) 的情况下,仅通过预测坐标点序列来实现高精度图像分割的可能性:模型直接在其语言空间内预测描绘对象边界的点序列(文本坐标)。为了实现高保真度,我们引入了一个两阶段的SFT→RL训练流程,其中基于IoU 奖励的强化学习 ( RL ) 会优化点序列,使其与真实轮廓精确匹配。我们发现,标准的 MLLM 架构本身就具有强大的底层感知能力,无需任何专门的架构即可将其释放出来。在分割基准测试中,SimpleSeg 的性能与依赖复杂、特定任务设计的方法相当,甚至常常更胜一筹。这项工作表明,精确的空间理解可以从简单的点预测中涌现,挑战了目前对辅助组件的需求,并为更统一、更强大的虚拟语言模型 (VLM) 铺平了道路。
- 核心亮点:
- 极简主义: 将分割重构为 序列生成 (sequence generation) 问题,模型在语言空间内直接输出轮廓点坐标。
- 强化学习优化: 提出了 SFT → RL 训练流水线,利用基于 IoU (交并比) 的奖励机制来精细化点序列质量。
- 泛化能力: 在 refCOCO 等基准测试上超越了许多拥有复杂任务特定设计的模型
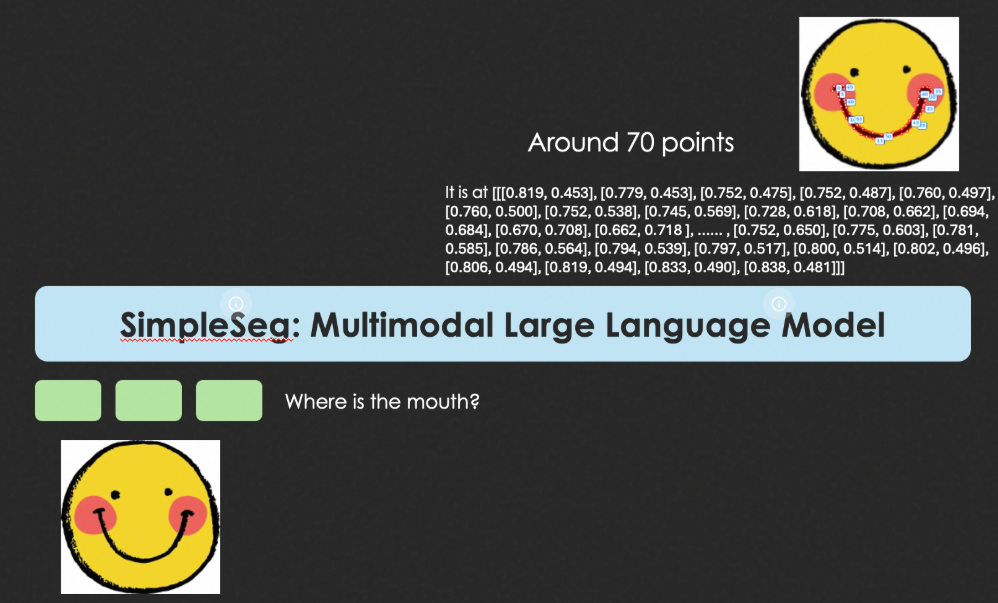
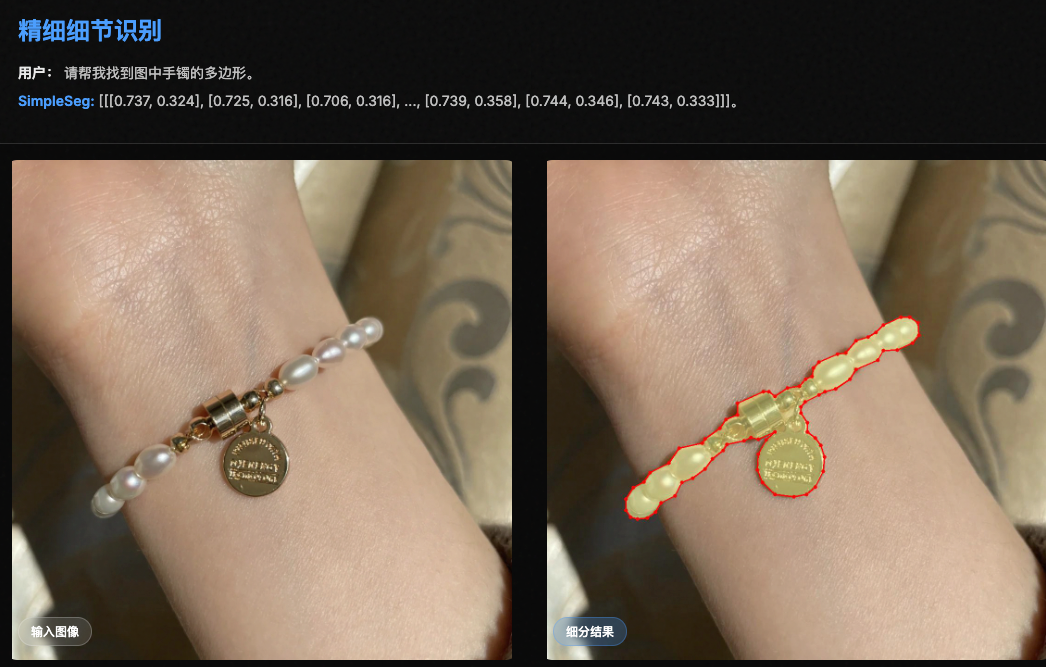

BaseCV
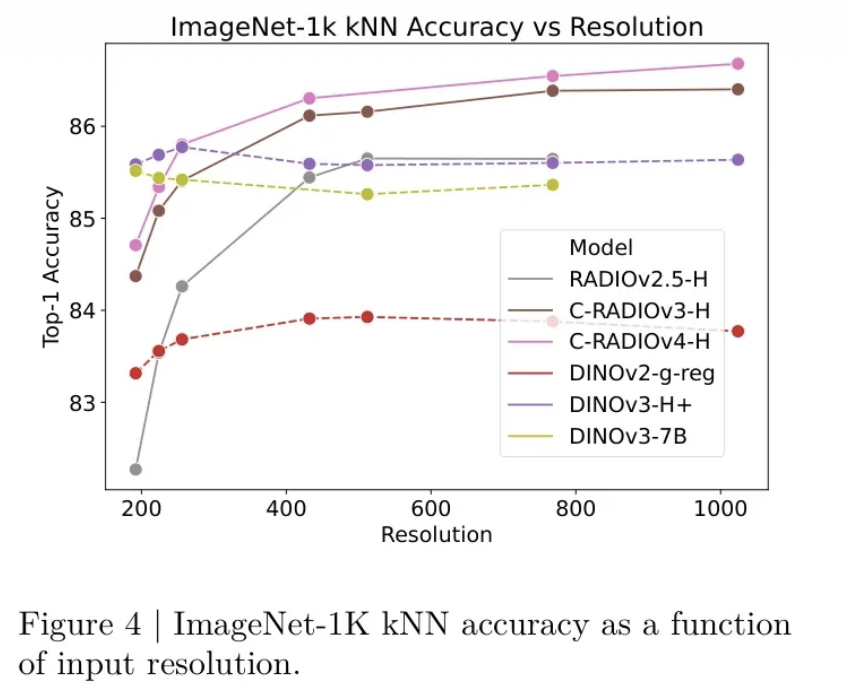
C-RADIOv4: https://arxiv.org/abs/2601.17237
机构: Nvidia
C-RADIOv4最大的变化在于教师阵容的全面升级。相比前代使用的DFN CLIP、DINOv2和SAM,本次采用了当前各领域的最强模型:
- SigLIP2-g-384:取代DFN CLIP,成为文本对齐的新标杆
- DINOv3-7B:自监督学习的巅峰之作,密集表征能力大幅提升
- SAM3:分割模型的最新版本,在复杂场景理解上更进一步
主要技术:
- 采用随机分辨率训练
- 平移等变损失:应该是对于输入图像进行patch为大小的移动,同时老师和学生需要看同一个裁剪区域(在学生和老师共见的空间位置中,将学生特征和老师特征空间进行对齐映射)
- 损失权重平衡
Low-Level
Revisiting Lightweight Low-Light Image Enhancement: From a YUV Color Space Perspective https://www.arxiv.org/abs/2601.17349
机构: Vivo
- 内容简介: 该研究从 YUV 颜色空间 的频域视角重新审视了微光增强任务 (L3IE),旨在解决移动设备上的性能与体积平衡问题:在当今移动互联网时代,轻量级低光图像增强(L3IE)对于移动设备至关重要,因为移动设备始终面临着视觉质量和模型紧凑性之间的权衡。尽管近期的方法采用解耦策略来简化轻量级架构设计,例如 Retinex 理论和 YUV 色彩空间变换,但它们的性能从根本上受到限制,因为它们忽略了特定通道的退化模式和跨通道交互作用。为了弥补这一不足,我们进行了频域分析,证实了 YUV 色彩空间在 L3IE 中的优越性。我们发现了一个关键洞察:Y 通道主要丢失低频内容,而 UV 通道则受到高频噪声的干扰。基于这一发现,我们提出了一种新颖的基于 YUV 的范式,该范式策略性地使用以下模块恢复通道:Y 通道采用双流全局-局部注意力模块,UV 通道采用 Y 通道引导的局部感知频率注意力模块,以及用于最终特征融合的引导交互模块。大量实验验证了我们的模型在多个基准测试中达到了新的最先进水平,以显著减少的参数数量提供了卓越的视觉质量。
- 核心亮点:
- 极度轻量: 模型参数量仅为 30K,设置了新的效率基准。
- 频域解耦: 发现 Y 通道主要丢失低频能量,而 UV 通道受高频噪声干扰,据此设计了特定的处理模块。
- 性能优异: 在 GPU 上延迟仅为 6.5ms,并在多个微光增强基准测试中刷新了 SOTA 记录

